
Authors:
(1) Deborah Miori, Mathematical Institute, University of Oxford, Oxford, UK and 2Oxford-Man Institute of Quantitative Finance, Oxford, UK (Corresponding author: Deborah Miori, [email protected]);
(2) Constantin Petrov, Fidelity Investments, London, UK.
Table of Links
Conclusions, Acknowledgements, and References
3 Framework
3.1 Natural Language Processing for Topic Modeling
Natural Language Processing (NLP) has undergone significant advancements in recent years, revolutionising the field of computational linguistics. One of the noticeable but challenging applications of NLP is topic analysis, a technique that involves the extraction of latent themes and subjects from extensive textual corpora. Among the first methodologies proposed for such task, there is Latent Dirichlet Allocation (LDA) [6].
LDA first transforms each document of a corpus into a set of words with related Term Frequency - Inverse Document Frequency (TF-IDF) value, which is a measure of relative importance of words across documents. This is computed as
TF-IDF = TERM FREQUENCY (TF) × INVERSE DOCUMENT FREQUENCY (IDF), (2)
where TF is the count of a target word in the current document considered (normalised by the total number of words in the document), and IDF is the inverse of the count of occurrences of such word in the whole set of documents (normalised by the total number of documents). Intuitively, the TF-IDF words’ weights per document are lower if the word appears in more documents and so does not carry strong characterisation power, but higher if instead it appears often in just one specific document. Then, LDA assumes that each document is generated from a collection of topics in some certain proportion, and that each topic is itself a group of dominant keywords with specific probability distribution. Consequently, we can try to back-engineer the root topics used to generate a large collection of documents, by analysing the co-occurrence of individual tokens and looking for the joint probability distribution of our given observable and target variables. However, the task of assigning a meaningful label to each set of terms (i.e. forming a topic) must be done by the user.
Then, a big advancement in topic modeling arose with the introduction of BERTopic [9], built upon the Bidirectional Encoder Representations from Transformers (BERT) language model. BERTopic generates document embedding with pre-trained transformer-based language models, clusters these embeddings, and finally, generates topic representations with a class-based variant of the TF-IDF procedure[2]. However, multiple weaknesses are still characteristic of this technique. The model assumes that each document contains only one single topic, and words in a topic result to be often very similar to one another and redundant for the interpretation of the topic itself. Polysemy (i.e. when words have multiple meanings in different contexts) is also a further challenge. Thus, reliable and systematic downstream applications of BERTopic are considered difficult to achieve.
Generative Pre-trained Transformers (i.e. GPT models) represent a groundbreaking advancement in the realm of NLP and artificial intelligence (AI), due to their remarkable ability to understand and generate human-like text. A GPT model is a decoder-only transformer model of a deep neural network, which uses attention to selectively focus on segments of input text that it predicts to be the most relevant. It is extensively pre-trained and has been proven to achieve groundbreaking accuracy on multiple multimodal tasks [14]. Despite there have not been related advancements on systematic topic modeling yet, we propose a novel methodology that uses it to achieve indeed such scope.
GPTs and downstream extraction of topics and narratives. As introduced in Subsection 2.1, our news data are descriptive textual content, that we instead aim to analyse quantitatively. Our goal is to extract information on the development of topics and narratives in a systematic but interpretable way. We did experiment with the early topic modeling methodologies described above, but found strong limitations (e.g. labeling the topics from LDA and BERTopic is oftentimes highly subjective and challenging, and such topics can extensively overlap, making it difficult to distinguish between them). Thus, we decided to leverage on the proven ability of the GPT3.5 model to complete tasks of summary composition, sentiment analysis, and entity extraction [15], to achieve our goal. We could of course have directly questioned GPT models for topics and narratives characteristic of news articles, but their inherent randomness and lengthiness in the formulation of answers makes it difficult to identify comparable and reliable results, to then use for downstream tasks.
GPT3.5 is thus used on our corpus of news, to first do data reformatting. For each one article, we extract:
-
a ranking of the five most important “entities” discussed in the text, with related sentiment scores ∈ [−1, +1],
-
a ranking of the five most important “concepts” discussed in the text, with related sentiment scores ∈ [−1, +1],
-
the overall sentiment of the article, both as GPT sentiment score and from the basic VADER technique [16],
-
a one sentence summary of the article,
-
an abstract of the article up to twenty sentences long.
The keywords “entities” and “concepts” are chosen to either focus more on common and proper nouns, or adding a tuning on abstractions that describe categories of objects, respectively. Importantly, we employ prompt engineering techniques to generate more accurate and useful responses, and lower GPT temperature parameter to 0.2 to make the outputs more structured. We also iteratively refine our requests, and manually compare a sample of results to the actual news text, to assess the quality of GPT parsing. As an example, we propose here the main prompt used:
• prompt0 = " I am an International Economist. Give me the top five entities mentioned in this text, from the most to least important. Reply as a numbered list using one or two words per entity at most. Next to each entity, provide the sentiment about this entity after a /-symbol strictly as a number between -1 and +1. Do not use words or brackets."
Our hypothesis is that focusing on such keywords of news (that become our fundamental building blocks), and the inherent interconnections that we can define by their membership to one same article, will allow us to identify topics and narratives within news. Thus, we now introduce the relevant concepts from network analysis to model and analyse such interconnections.
3.2 Network Analysis
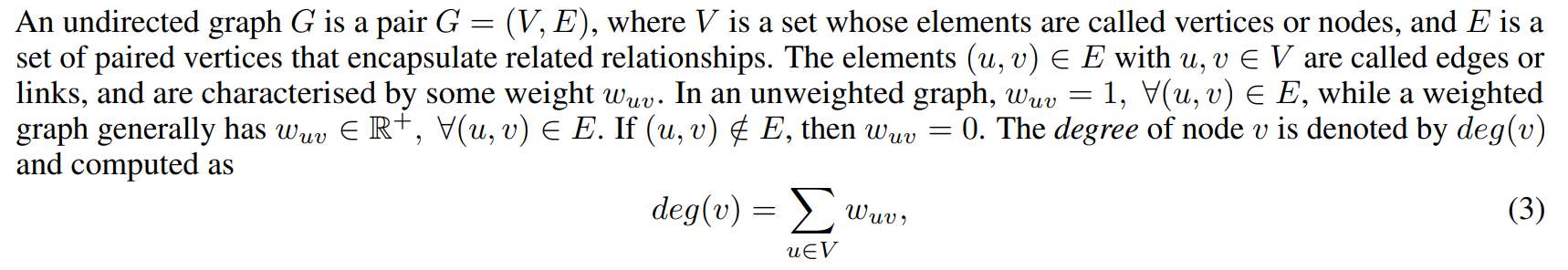
which is often the first measure used to gauge the importance of the different nodes in a graph.

Importantly, we highlight that it is common to compute the above and further measures on the giant component of a graph. The giant component is the largest connected component of the graph (i.e. the subgraph with highest number of nodes), for which there is a path connecting each pair of nodes belonging to such subgraph.
Community detection - primer. Another important field of research within graph theory is community detection, i.e. clustering tightly connected groups of nodes, which is usually achieved by maximising the modularity Q of the partition proposed. Modularity Q is computed following [17] and measures the strength of division of a network into modules. Mathematically,

Community detection - fuzziness. Another important branch of community detection algorithms relies on spectral methods. Within such approaches, it is common to consider the connectivity of a graph via its Laplacian matrix L, i.e.
L = D − A, (7)
where D is the diagonal matrix summarising degrees of nodes. Since such matrix is positive semi-definite, then it can be decomposed into the product of a real matrix and its transpose. The new matrix can be interpreted as an embedding for nodes in the graph, or further clustered to highlight suggested communities. In [19], the authors consider the negative Laplacian H = −L of a graph as an encryption of its local structure. In full,
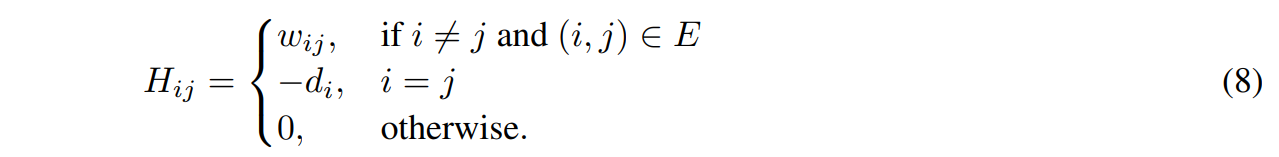
Then, they apply to it a diffusion equation evolved by an exponential kernel. This is done in order to extract long-range relationships, and reads

3.3 Embeddings
As already made explicit, our work relies upon the application of both NLP and network analysis techniques. We extract main entities and concepts characteristic of news thanks to GPT, and these become our fundamental building block for network generation (where the related details will be fully explained in Section 4). To thoroughly analyse such landscape of data, we will also leverage upon
-
the word2vec [20] embedding techniques for words,
-
the node2vec [21] embedding techniques for nodes in a graph.
The former methodology considers sentences as directed subgraphs with nodes as words, and uses a shallow two-layer neural network (NN) to map each word to a unique vector. The result is that words sharing a common context in the corpus of sentences lie closer to each other. The latter approach focuses on embedding nodes into low-dimensional vector spaces by first using random walks to construct a network neighbourhood of every node in the network, and then optimising an objective function with network neighbourhoods as input.
Words embeddings - benchmark methodology. Word2vec [20] is a seminal method in NLP for word embedding, which operates on the premise that words with similar meanings share similar contextual usage. This approach employs two core models, i.e. either the Continuous Bag of Words (CBOW) or Skip-gram one. In CBOW, the algorithm predicts a target word from its surrounding context, while Skip-gram predicts context words given a target word. Utilising neural networks, these models generate and adjust word vectors to minimise prediction errors. The resulting high-dimensional vectors encode semantic relationships among words, and they are widely applied in various NLP tasks, such as sentiment analysis, text classification, and machine translation. Despite dating back to 2013, word2vec is indeed still a state-of-the-art methodology for the task of words (and bigrams...) embeddings, since e.g. GPT models are not able to provide such micro-level embeddings.
We can thus identify vectors for our entities extracted from news, by leveraging on pre-trained word2vec models available online, and cluster them. This provides us with a very first benchmark for topic identification and characterisation of their evolution over weeks, before moving to study the effect of graph constructs. However, the best pre-trained models available to us tend to be based on old sets of text (∼ up to 2015) and are not frequently updated. Since we do not have the resources to train our own model, this implies that we will surely miss vectors for meaningful words such as “Covid-19”, “Bitcoin”..., and that the results cannot consequently be considered for more than initial exploratory investigations. In any case, the two pre-trained models we use to generate embeddings are:
-
Gensim Google News[3], which is a word embedding model based on Google news. A 300-dimensional vector representation is provided for approximately three million tokens (∼ words).
-
FinText[4] Skip-gram [22], which is a financial word embedding based on Dow Jones Newswires Text News Feed Database. Again, a 300-dimensional representation is provided for almost three million tokens.

3.4 Logistic Regression
For completeness, we now briefly recall the logistic regression (also known as logit) statistical model. Logistic regression estimates the probability P(X) of a binary event Y occurring or not, based on a given set X = (X1, ..., Xn) of n independent variables, i.e. predictors, for the instance under consideration. In our case, we can leverage on such a framework to test which news’ features might relate to moment of market dislocations (as per our definition on z-scores).
In logistic regression, probability 0 ≤ P(X) ≤ 1 is defined via the logistic function
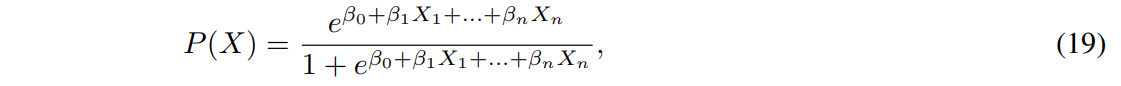
which can be re-written in its logit version as
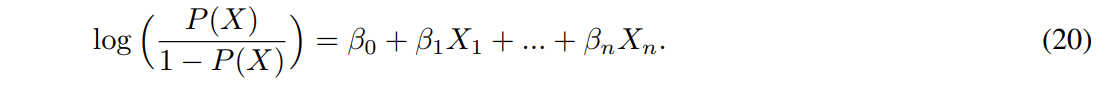

Finally, it is often the case that prediction classes are strongly imbalanced, and it is needed to over-sample the minority class in the training set for better results. In our case, we leverage on the well-known SMOTE (Synthetic Minority Over-sampling Technique) algorithm [24] for the purpose, which generates synthetic perturbations of instances in the minority class to achieve indeed a more general decision region for the prediction of these less frequent events. As a side note, we also mention that other machine learning techniques can be of course used for classification and prediction in a framework such as ours (e.g. classification trees, random forests...). However, logistic regression is indeed the final technique adopted in our work, since we simply aim to complete an initial assessment of whether news structure, especially modelled by our graph construct, can provide any enhancement to our understanding of markets.
This paper is available on arxiv under CC0 1.0 DEED license.
[2] https://maartengr.github.io/BERTopic/api/ctfidf.html
[3] https://github.com/RaRe-Technologies/gensim-data#models
[4] https://www.idsai.manchester.ac.uk/wp-content/uploads/sites/324/2022/06/Eghbal-Rahimikia.pdf