

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Jiwan Chung, MIR Lab Yonsei University (https://jiwanchung.github.io/);
(2) Youngjae Yu, MIR Lab Yonsei University (https://jiwanchung.github.io/).
Table of Links
- Abstract and Intro
- Method
- Experiments
- Related Work
- Conclusion
- Limitations and References
- A. Experiment Details
- B. Prompt Samples
Abstract
Large language models such as GPT-3 have demonstrated an impressive capability to adapt to new tasks without requiring task-specific training data. This capability has been particularly effective in settings such as narrative question answering, where the diversity of tasks is immense, but the available supervision data is small. In this work, we investigate if such language models can extend their zero-shot reasoning abilities to long multimodal narratives in multimedia content such as drama, movies, and animation, where the story plays an essential role. We propose Long Story Short, a framework for narrative video QA that first summarizes the narrative of the video to a short plot and then searches parts of the video relevant to the question. We also propose to enhance visual matching with CLIPCheck. Our model outperforms state-of-the-art supervised models by a large margin, highlighting the potential of zero-shot QA for long videos.
1. Introduction
Recent video QA models face challenges in handling long video narrative QA tasks [2, 13, 27] (i.e., films, dramas, and YouTube web videos) due to the limitation in data and annotations. This results in an inability to comprehend the long video narratives beyond answering mainly visual questions on short video clip [16, 17, 30]. The sizes of such long video QAs are insufficient to train the models to fully comprehend the complex narrative structures within a video, yielding sub-optimal performances. [10] demonstrate that the supervised models rely more on language biases in the question than the narrative context: they can obtain similar performance even without seeing any video context. This highlights the necessity of multimodal reasoning capability beyond small task-specific supervision.
To address the challenge caused by low generalization, a zero-shot approach using pretrained Large Language Models (LLMs) can be an efficient alternative for tackling complex QA tasks [32], and text context summarization [8, 37]. Yet, is the narrative QA capability of such LLMs transferable to the video domain?
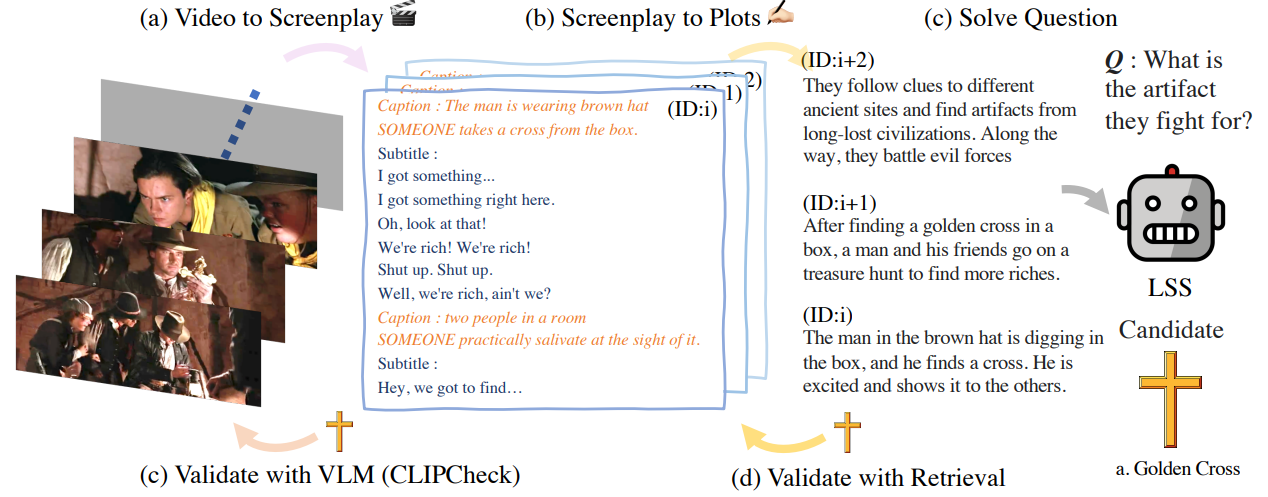
We propose Long Story Short (LSS), illustrated in figure 1, that translates video clips into text screenplay format inspired by Socratic Model [35]. Using GPT-3 [1], we first summarize the long video into a list of plots and then navigate both the generated summary and the raw video context to resolve the given question. Our zero-shot method shows better results than state-of-the-art supervised methods in MovieQA and DramaQA dataset. Furthermore, we propose CLIPCheck, a visual-text matching method to enhance visual alignment of the reasoning results provided by GPT-3. To summarize, our main contributions are three-fold:
-
We present LSS, a framework that summarizes a long video narrative to a list of plots and retrieves the subplot relevant to the question.
-
We demonstrate the importance of considering visual alignment strength via CLIPbased matching in visual prompting.
-
Our zero-shot approach achieves state-of-the-art performance in MovieQA [27] and DramaQA [2], outperforming supervised baselines.