Authors:
(1) Xiao-Yang Liu, Hongyang Yang, Columbia University (xl2427,hy2500@columbia.edu);
(2) Jiechao Gao, University of Virginia (jg5ycn@virginia.edu);
(3) Christina Dan Wang (Corresponding Author), New York University Shanghai (christina.wang@nyu.edu).
Table of Links
2 Related Works and 2.1 Deep Reinforcement Learning Algorithms
2.2 Deep Reinforcement Learning Libraries and 2.3 Deep Reinforcement Learning in Finance
3 The Proposed FinRL Framework and 3.1 Overview of FinRL Framework
3.5 Training-Testing-Trading Pipeline
4 Hands-on Tutorials and Benchmark Performance and 4.1 Backtesting Module
4.2 Baseline Strategies and Trading Metrics
4.5 Use Case II: Portfolio Allocation and 4.6 Use Case III: Cryptocurrencies Trading
5 Ecosystem of FinRL and Conclusions, and References
ABSTRACT
Deep reinforcement learning (DRL) has been envisioned to have a competitive edge in quantitative finance. However, there is a steep development curve for quantitative traders to obtain an agent that automatically positions to win in the market, namely to decide where to trade, at what price and what quantity, due to the error-prone programming and arduous debugging. In this paper, we present the first open-source framework FinRL as a full pipeline to help quantitative traders overcome the steep learning curve. FinRL is featured with simplicity, applicability and extensibility under the key principles, full-stack framework, customization, reproducibility and hands-on tutoring
Embodied as a three-layer architecture with modular structures, FinRL implements fine-tuned state-of-the-art DRL algorithms and common reward functions, while alleviating the debugging workloads. Thus, we help users pipeline the strategy design at a high turnover rate. At multiple levels of time granularity, FinRL simulates various markets as training environments using historical data and live trading APIs. Being highly extensible, FinRL reserves a set of user-import interfaces and incorporates trading constraints such as market friction, market liquidity and investor’s risk-aversion. Moreover, serving as practitioners’ stepping stones, typical trading tasks are provided as step-by-step tutorials, e.g., stock trading, portfolio allocation, cryptocurrency trading, etc.
1 INTRODUCTION
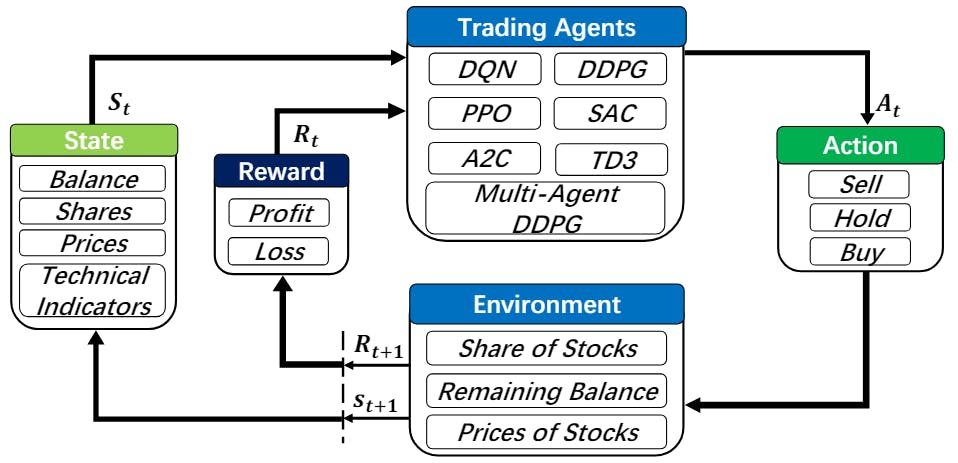
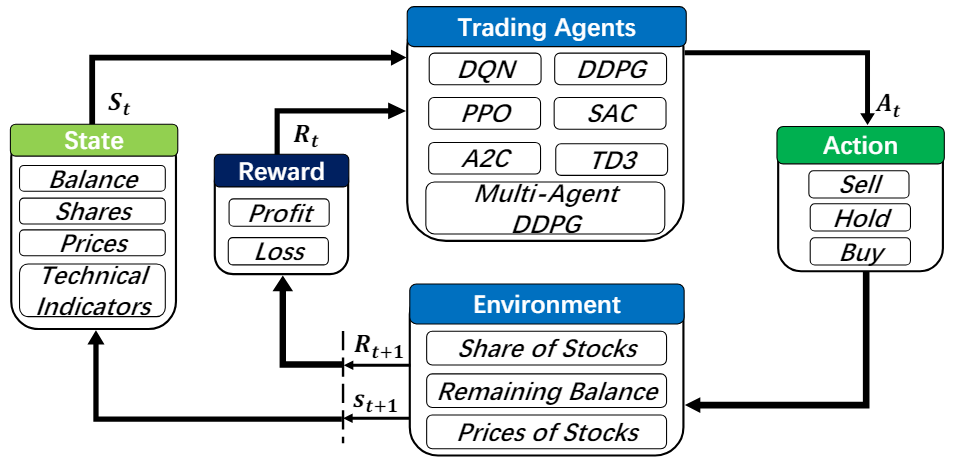
Deep reinforcement learning (DRL), that balances exploration (of uncharted territory) and exploitation (of current knowledge), is a promising approach to automate trading in quantitative finance [50][51][47][54][21][13]. DRL algorithms are powerful in solving dynamic decision-making problems by learning through interactions with an unknown environment and offer two major advantages of portfolio scalability and market model independence [6]. In quantitative finance, algorithmic trading is essentially making dynamic decisions, namely, to decide where to trade, at what price and what quantity, in a highly stochastic and complex financial market. Incorporating many financial factors, as shown in Fig. 1, a DRL trading agent builds a multi-factor model to trade automatically, which is difficult for human traders to accomplish [4, 53]. Therefore, DRL has been envisioned to have a competitive edge in quantitative finance.
Many existing works have applied DRL in quantitative financial tasks. Both researchers and industry practitioners are actively designing trading strategies fueled by DRL, since deep neural networks are significantly powerful at estimating the expected return of taking a certain action at a state. Moody and Saffell [33] utilized a policy search for stock trading; Deng et al. [9] showed that DRL can obtain more profits than conventional methods. More applications include stock trading [35, 47, 51, 54], futures contracts [54], alternative data (news sentiments) [22, 35], high frequency trading [15], liquidation strategy analysis [3], and hedging [6]. DRL is also being actively explored in the cryptocurrency market, e.g., automated trading, portfolio allocation, and market making.
However, designing a DRL trading strategy is not easy. The programming is error-prone with tedious debugging. The development pipeline includes preprocessing market data, building a training environment, managing trading states, and backtesting trading performance. These steps are standard for implementation but yet time consuming especially for beginners. Therefore, there is an urgent demand for an open-source library to help researchers and quantitative traders to overcome the steep learning curve.
In this paper, we present a FinRL framework that automatically streamlines the development of trading strategies, so as to help researchers and quantitative traders to iterate their strategies at a high turnover rate. Users specify the configurations, such as picking data APIs and DRL algorithms, and analyze the performance of trading results. To achieve this, FinRL introduces a three-layer framework. At the bottom is an environment layer that simulates financial markets using actual historical data, such as closing price, shares, trading volume, and technical indicators. In the middle is the agent layer that implements fine-tuned DRL algorithms and common reward functions. The agent interacts with the environment through properly defined reward functions on the state space and action space. The top layer includes applications in automated trading, where we demonstrate several use cases, namely stock trading, portfolio allocation, cryptocurrency trading, etc. We provide baseline trading strategies to alleviate debugging workloads.
Under the three-layer framework, FinRL is developed with three primary principles:
• Full-stack framework. To provide a full-stack DRL framework with finance-oriented optimizations, including market data APIs, data preprocessing, DRL algorithms, and automated backtesting. Users can transparently make use of such a development pipeline.
• Customization. To maintain modularity and extensibility in development by including state-of-the-art DRL algorithms and supporting design of new algorithms. The DRL algorithms can be used to construct trading strategies by simple configurations.
• Reproducibility and hands-on tutoring. To provide tutorials such as step-by-step Jupyter notebooks and user guide to help users walk through the pipeline and reproduce the use cases.
This leads to a unified framework where developers are able to efficiently explore ideas through high-level configurations and specifications, and to customize their own strategies at request.
Our contributions are summarized as follows:
• FinRL is the first open-source framework that demonstrates the great potential of applying DRL algorithms in quantitative finance. We build an ecosystem around the FinRL framework, which seeds the rapidly growing AI4Finance community.
• The application layer provides interfaces for users to customize FinRL to their own trading tasks. Automated backtesting module and performance metrics are provided to help quantitative traders iterate trading strategies at a high turnover rate. Profitable trading strategies are reproducible and hands-on tutorials are provided in a beginner-friendly fashion. Adjusting the trained models to the rapid changing markets is also possible.
• The agent layer provides state-of-the-art DRL algorithms that are adapted to finance with fine-tuned hyperparameters. Users can add new DRL algorithms.
• The environment layer includes not only a collection of historical data APIs, but also live trading APIs. They are reconfigured into standard OpenAI gym-style environments [5]. Moreover, it incorporates market frictions and allows users to customize the trading time granularity.
The remainder of this paper is organized as follows. Section 2 reviews related works. Section 3 presents the FinRL framework. Section 4 demonstrates benchmark trading tasks using FinRL. We conclude this paper in Section 5.
This paper is available on arxiv under CC BY 4.0 DEED license.