

Authors:
(1) Gonzalo J. Aniano Porcile, LinkedIn;
(2) Jack Gindi, LinkedIn;
(3) Shivansh Mundra, LinkedIn;
(4) James R. Verbus, LinkedIn;
(5) Hany Farid, LinkedIn and University of California, Berkeley.
Table of Links
4. Results
Our baseline training and evaluation performance is shown in Table 2. The evaluation is broken down based on whether the evaluation images contain a face or not (training images contained only faces) and whether the images were generated with the same (in-engine) or different (out-of-engine) synthesis engines as those used in training (see Section 2.6). In order to provide a direct comparison of the true positive rate[8] (TPR) for the training and evaluation, we adjust the final classification threshold to yield a false positive rate[9] (FPR) of 0.5%.
With a fixed FPR of 0.5%, AI-generated faces are correctly classified in training and evaluation at a rate of 98%. Across different synthesis engines (StyleGAN 1,2,3, Stable Diffusion 1,2, and DALL-E 2) used for training, TPR was varied somewhat from a low of 93.3% for Stable Diffusion 1 to a high of 99.5% for StyleGAN 2, and 98.9% for StyleGAN1, 99.9% for StyleGAN3, 94.9% for Stable Diffusion 2, and 99.2% for DALL-E 2.
For faces generated by synthesis engines not used in
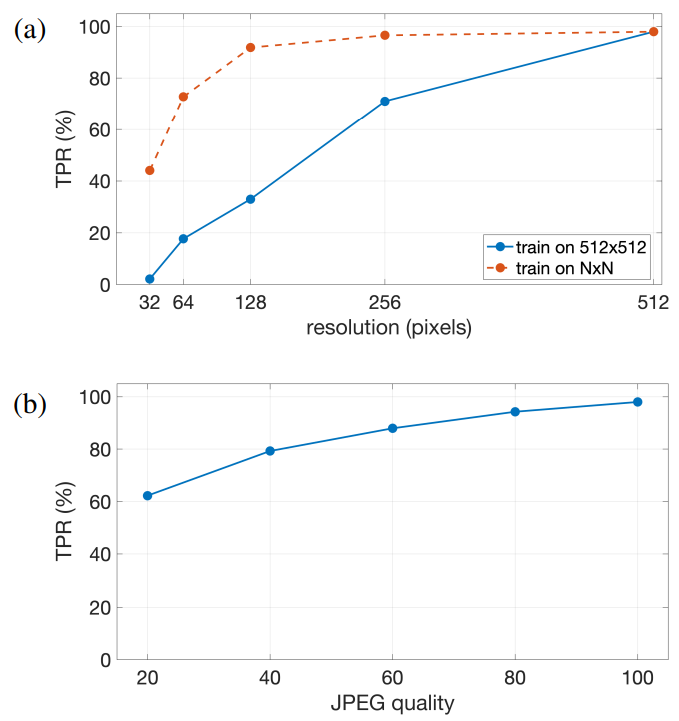
training (out-of-engine), TPR drops to 84.5% at the same FPR, showing good but not perfect out-of-domain generalization. Across the different synthesis engines not used in training, TPR varied widely with a low of 19.4% for Midjourney to a high of 99.5% for EG3D, and 95.4% for generated.photos. Our classifier generalizes well in some cases, and fails in others. This limitation, however, can likely be mitigated by incorporating these out-of-engine images into the initial training.
In a particularly striking result, non-faces – generated by the same synthesis engines as used in training – are all incorrectly classified. This is most likely because some of our real images contain non-faces (see Section 2.1) while all of the AI-generated images contain faces. Since we are only interested in detecting fake faces used to create an account, we don’t see this as a major limitation. This result also suggests that our classifier has latched onto a specific property of an AI-generated face and not some low-level artifact from the underlying synthesis (e.g., a noise fingerprint [8]). In Section 4.1, we provide additional evidence to support this hypothesis.
The above baseline results are based on training and evaluating images at a resolution of 512×512 pixels. Shown in Figure 3(a) (solid blue) is the TPR when the training images are down scaled to a lower resolution (256, 128, 64, and 32) and then up scaled back up to 512 for classification. With the same FPR of 0.5%, TPR for classifying an AI-generated face drops fairly quickly from a baseline of 98.0%.
The true positive rate, however, improves significantly when the model is trained on images at a resolution of N × N (N = 32, 64, 128, or 256) and then evaluated against the same TPR seen in training, Figure 3(a) (dashed red). As before, the false positive rate is fixed at 0.5%. Here we see that TPR at a resolution of 128 × 128 remains relatively high (91.9%) and only degrades at the lowest resolution of 32×32 (44.1%). The ability to detect AI-generated faces at even relatively low resolutions suggests that our model has not latched onto a low-level artifact that would not survive this level of down-sampling.
Shown in Figure 3(b) is the TPR of the classifier, trained on uncompressed PNG and JPEG images of varying quality, evaluated against images across a range of JPEG qualities (ranging from the highest quality of 100 to the lowest quality of 20). Here we see that TPR for identifying an AIgenerated face (FPR is 0.5%) degrades slowly with a TPR of 94.3% at quality 80 and a TPR of 88.0% at a quality of 60. Again, the ability to detect AI-generated faces in the presence of JPEG compression artifacts suggests that our model has not latched onto a low-level artifact.
4.1. Explainability
As shown in Section 4, our classifier is highly capable of distinguishing AI faces generated from a range of different synthesis engines. This classifier, however, is limited to only faces, Table 2. That is, when presented with non-face images from the same synthesis engines as used in training, the classifier completely fails to classify them as AI-generated.
We posit that our classifier may have learned a semanticlevel artifact. This claim is partly supported by the fact that our classifier remains highly accurate even at resolutions as low as 128×128 pixels, Figure 3(a), and remains reasonably accurate even in the face of fairly aggressive JPEG compression, Figure 3(b). Here we provide further evidence to support this claim that we have learned a structural- or semantic-level artifact.
It is well established that while general-purpose object recognition in the human visual system is highly robust to object orientation, pose, and perspective distortion, face recognition and processing are less robust to even a simple inversion [27]. This effect is delightfully illustrated in the classic Margaret Thatcher illusion [31]. The faces in the top row of Figure 4 are inverted versions of those in the bottom row. In the version on the right, the eyes and mouth are inverted relative to the face. This grotesque feature cocktail is obvious in the upright face but not in the inverted face.
We wondered if our classifier would struggle to classify
![Figure 4. The Margaret Thatcher illusion [31]: the faces in the top row are inverted versions of those on the bottom row. The eye and mouth inversion in the bottom right is evident when the face is upright, but not when it is inverted. (Credit: Rob Bogaerts/Anefo https://commons.wikimedia.org/w/index.php? curid=79649613))](https://cdn.hackernoon.com/images/fWZa4tUiBGemnqQfBGgCPf9594N2-8293uzi.png)
vertically inverted faces. The same 10,000 validation images (Section 2.6) were inverted and re-classified. With the same fixed FPR of 0.5%, TPR dropped by 20 percentage points from 98.0% to 77.7%.
By comparison, flipping the validation images about just the vertical axis (i.e., left-right flip) yields no change in the TPR of 98.0% with the same 0.5% FPR. This pair of results, combined with the robustness to resolution and compression quality, suggest that our model has not latched onto a low-level artifact, and may have instead discovered a structural or semantic property that distinguishes AI-generated faces from real faces.
We further explore the nature of our classifier using the method of integrated gradients [28]. This method attributes the predictions made by a deep network to its input features. Because this method can be applied without any changes to the trained model, it allows us to compute the relevance of each input image pixel with respect to the model’s decision.
Shown in Figure 5(a) is the unsigned magnitude of the normalized (into the range [0, 1]) integrated gradients averaged over 100 StyleGAN 2 images (because the StyleGANgenerated faces are all aligned, the averaged gradient is consistent with facial features across all images). Shown in Figure 5(b)-(e) are representative images and their normalized integrated gradients for an image generated by DALL-2, Midjourney, Stable Diffusion 1, and Stable Diffusion 2. In all cases, we see that the most relevant pixels, corresponding to larger gradients, are primarily focused around the facial region and other areas of skin.
4.2. Comparison
Because it focused specifically on detecting GANgenerated faces, the work of [23] is most directly related to ours. In this work, the authors show that a low-dimensional linear model captures the common facial alignment of StyleGAN-generated faces. Evaluated against 3,000 StyleGAN faces, their model correctly classifies 99.5% of the GAN faces with 1% of real faces incorrectly classified as AI. By comparison, we achieve a similar TPR, but with a lower 0.5% FPR.
Unlike our approach, however, which generalizes to other GAN faces like generated.photos, TPR for this earlier work drops to 86.0% (with the same 1% FPR). Furthermore, this earlier work fails to detect diffusion-based faces because these faces simply do not contain the same alignment artifact as StyleGAN faces. By comparison, our technique generalizes across GAN- and diffusion-generated faces and to synthesis engines not seen in training.
We also evaluated a recent state-of-the-art model that exploits the presence of Fourier artifacts in AI-generated images [8]. On our evaluation dataset of real and in-engine AIgenerated faces this model correctly classifies only 23.8% of the AI-generated faces at the same FPR of 0.5%. This TPR is considerably lower than our model’s TPR of 98.0% and also lower than 90% TPR reported in [8]. We hypothesize that this discrepancy is due to the more diverse and challenging in-the-wild real images of our dataset.
This paper is available on arxiv under CC 4.0 license.
[8] True positive rate (TPR) is the fraction of AI-generated photos that are correctly classified.
[9] False positive rate (FPR) is the fraction of real photos that are incorrectly classified.