
Authors:
(1) Xiaofei Sun, Zhejiang University;
(2) Xiaoya Li, Shannon.AI and Bytedance;
(3) Shengyu Zhang, Zhejiang University;
(4) Shuhe Wang, Peking University;
(5) Fei Wu, Zhejiang University;
(6) Jiwei Li, Zhejiang University;
(7) Tianwei Zhang, Nanyang Technological University;
(8) Guoyin Wang, Shannon.AI and Bytedance.
Table of Links
LLM Negotiation for Sentiment Analysis
4 Experiments
To evaluate the effectiveness of the proposed method, we use GPT-3.5, GPT-4 (OpenAI, 2023) and InstructGPT3.5 (Ouyang et al., 2022) [1] as backbones for the multi-model negotiation method. In this process, we use the fine-tuned RoBERTa-Large (Liu et al., 2019) as the similarity function for retrieving k nearest neighbors as demonstrations.
In the empirical study, we investigate the following three distinct ICL approaches, offering insights of integrating such methods for sentiment analysis.
• Vanilla ICL: the sentiment analysis task is finished by asking a LLM with a prompt to generate sentiment-intensive text without gradient updates. In practice, we conduct two sets of experiments under this setting with GPT3.5 and GPT-4, respectively.
• Self-Negotiation: the task is finished by using one LLM to discriminate and correct the answer generated by itself. We conduct two experiments with GPT3.5 and GPT-4 and get two results.
• Negotiation with two LLMs: the task is completed by employing two different LLMs to take turns performing as the answer generator and discriminator. Specifically, we conduct one set of experiment with GPT3.5 and GPT-4.
4.1 Datasets
We conduct experiments on six sentiment analysis datasets, including SST-2 (Socher et al., 2013), Movie Review (Zhang et al., 2015), Twitter (Rosenthal et al., 2019), Yelp-Binary (Zhang et al., 2015), AmazonBinary (Zhang et al., 2015), and IMDB (Maas et al., 2011b). More details of the datasets are shown as follows:
• SST-2 (Socher et al., 2013): SST-2 is a binary (i.e., positive, negative) sentiment classification dataset and contains movie review snippets from the Rotton Tomato. We follow Socher et al. (2013) and use the train, valid, test splits with the number of examples of 67,349, 872, 1,821, respectively.
• Movie Review (MR) (Zhang et al., 2015): Movie Reviews is a dataset for use in sentiment-analysis experiments. Available are collections of movie-review documents labeled with respect to their overall sentiment polarity (i.e., positive or negative).
• Twitter (Rosenthal et al., 2019): Twitter is a three-class (i.e., positive, negative, neutral) sentiment analysis dataset, aiming to detecting whether a piece of text expresses a sentiment polarity in respect to a specific topic, such as a person, a product, or an event. The dataset is origin a shared task at SemEval 2017, containing 50,333 examples in the train set and 12,284 examples in the test set.
• Yelp-Binary (Zhang et al., 2015): Yelp is a binary (i.e., positive, negative) sentiment analysis dataset, containing product reviews from Yelp. The dataset has 560,000 trainig samples and 38,000 testing samples.
• Amazon-Binary (Zhang et al., 2015): Amazon is a binary sentiment classification task, containing product reviews from Amazon with 3,600,000 examples in the train set and 400,000 examples in the test set.
• IMDB (Maas et al., 2011b): The IMDB dataset contains movie reviews along with their associated binary sentiment polarity labels. The dataset contains 50,000 reviews split evenly into 25k train and 25k test sets. The overall distribution of labels is balanced (25k positive and 25k negative).
We use accuracy as the evaluation metric.
4.2 Baselines
We use supervised neural network models and ICL approaches with LLMs as baselines for comparisons. For supervised methods, we choose the following four models:
• DRNN (Wang, 2018): incorporates positioninvariance into RNN and CNN models by limiting the distance of information flow in neural networks.
• RoBERTa (Liu et al., 2019): is a reimplementation of BERT (Devlin et al., 2018) aiming to improve performances on NLP downstream tasks. In this paper, we report results achieved by fine-tuned RoBERTa-Large.
• XLNet (Yang et al., 2019): is a pretrained autoregressive LM that integrates Transformer-XL (Dai et al., 2019) and enables to learn bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order.
• UDA (Xie et al., 2020): is short for Unsupervised Data Augmentation, which is a data augmentation strategy that employs a consistency loss function for unsupervised and supervised training stages. Performances in Table 1 are obtained by BERT-Large with UDA.
• BERTweet (Nguyen et al., 2020): is a pretrained language model for English Tweets. The BERTweet has the same number of parameters as RoBERTa-Base.
• EFL (Wang et al., 2021): is backboned by RoBERTa-Large and fine-tuned on natural language entailment examples.
For ICL approaches, we report experimental results with LLMs from the following studies:
• Zhang et al. (2023d): presents a comprehensive study for applying LLMs (i.e., FLan-UL2, T5 and ChatGPT) on sentiment analysis tasks. Experimental results in the Table 1 are obtained in few-shot(k = 5) settings.
• InstructGPT-3.5 (Ouyang et al., 2022): is a large language model trained to follow human instructions. Experimental results in the Table 1 are achieved by the text-davinci-003 model.
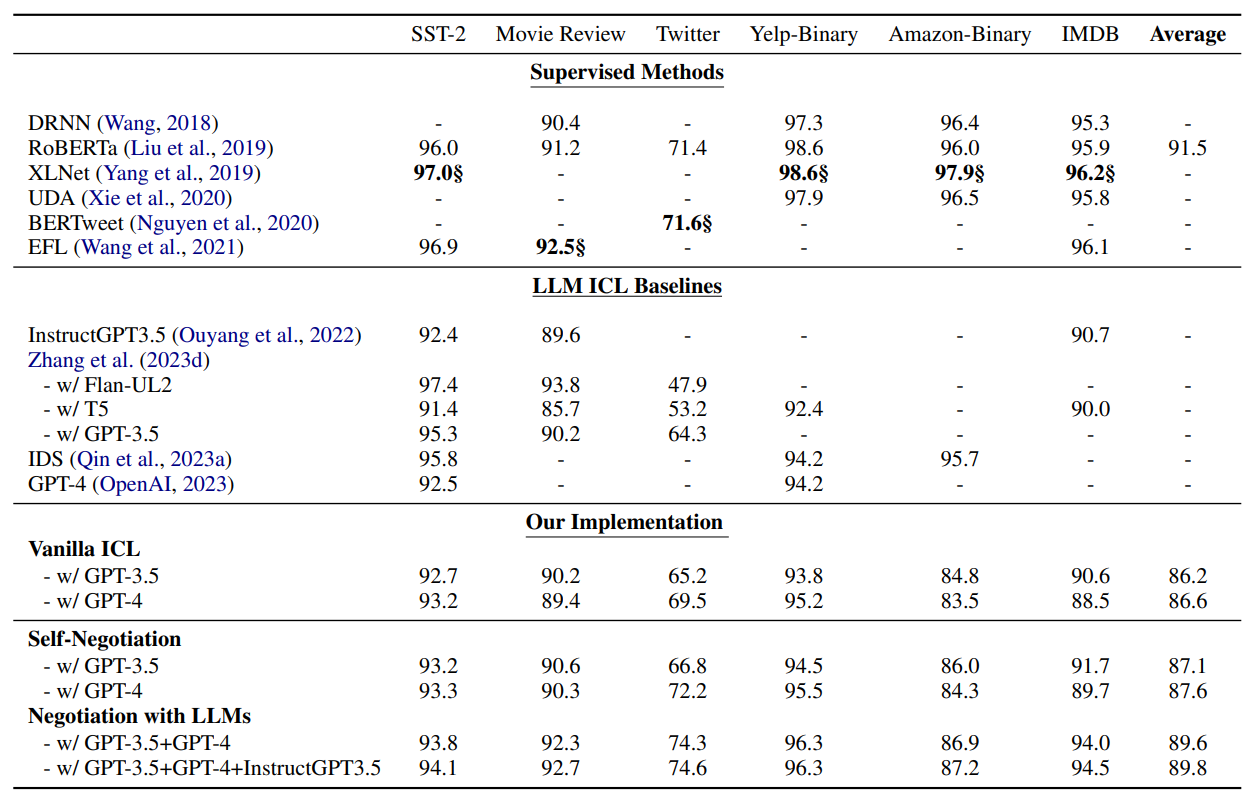
• IDS (Qin et al., 2023a): propose an Iterative Demonstration Selection (IDS) strategy to select demonstrations from diversity, similarity, and task-specific perspectives. Results shown in Table 1 are obtained by using GPT-3.5 (gpt-3.5-turbo).
• GPT-4 (OpenAI, 2023): is a large multimodal model, achieving human-level performance on various NLP benchmarks.
• Self-negotiation: The same LLM acts as both the roles of the generator and the discriminator.
4.3 Results and analysis
Experiment results are shown in Table 1. As can be seen in the table, compared to vanilla ICL, following the generate-discriminate paradigm with one LLM (self-negotiation) receives performance gains on six sentiment analysis datasets: GPT-3.5 gains +0.9 on average; GPT-4 receives +1.0 acc on average. This phenomenon illustrates that the LLM, performing as the answer discriminator, can correct a portion of errors caused by the task generator.
We also observe that using two different LLMs as the task generator and task discriminator in turn introduces significant performance improvements compared to merely using one model. Negotiations with two LLMs outperform the self-negotiation method by +1.7, +2.1, and +2.3 in terms of accuracy on MR, Twitter, IMDB datasets, respectively. The reason for this phenomenon is that using two different LLMs finish the sentiment analysis task through negotiations can take the advantage of different understandings of the given input and unleash the power of two LLMs, leading to more accurate decisions.
We also find that when introduce a third LLM to resolve the disagreement between the flippled-roled negotiations, additional performance boost can be obtained. This demonstrates that the third LLM can resolve conflicts between two LLMs through multiple negotiations and improve performances on the sentiment analysis task. It is noteworthy that the multi-model negotiation method outperforms the supervised method RoBERTa-Large by +0.9 on the MR dataset, and bridges the gap between vanilla ICL and the supervised method: achieving 94.1 (+1.4) accuracy on SST-2; 92.1 (+2.7) on Twitter; 96.3 (+2.5) on Yelp-2; 87.2 (+3.7) on Amazon-2; and 94.5 (+6.0) on IMDB dataset.
[1] text-davinci-003
This paper is available on arxiv under CC 4.0 license.