
Authors:
(1) Prerak Gandhi, Department of Computer Science and Engineering, Indian Institute of Technology Bombay, Mumbai, prerakgandhi@cse.iitb.ac.in, and these authors contributed equally to this work;
(2) Vishal Pramanik, Department of Computer Science and Engineering, Indian Institute of Technology Bombay, Mumbai, vishalpramanik,pb@cse.iitb.ac.in, and these authors contributed equally to this work;
(3) Pushpak Bhattacharyya, Department of Computer Science and Engineering, Indian Institute of Technology Bombay, Mumbai.
Table of Links
- Abstract and Intro
- Motivation
- Related Work
- Dataset
- Experiments and Evaluation
- Results and Analysis
- Conclusion and Future Work
- Limitations and References
- A. Appendix
6. Results and Analysis
We present our observations and evaluations. The nature of our task makes human evaluation take precedence over automatic evaluation (it is for automatic movie script generation, after all!). The qualitative analysis of our generated plots and scenes is based on feedback from 5 professional scriptwriters of our industry partner, the well-known media platform.
6.1. Plot Generation
6.1.1. Automatic Evaluation
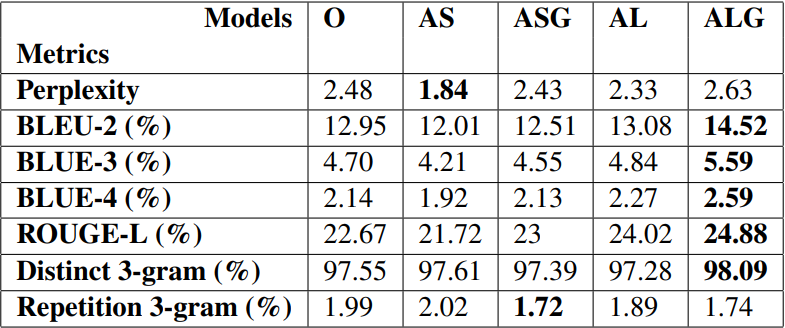
Table 1 shows auto-evaluation scores for the multiple GPT-3 plot generation models.

6.1.2. Human Rating
We conducted human evaluation on Hollywood annotated short input model. The evaluation was done by five groups of 3 people, with each group
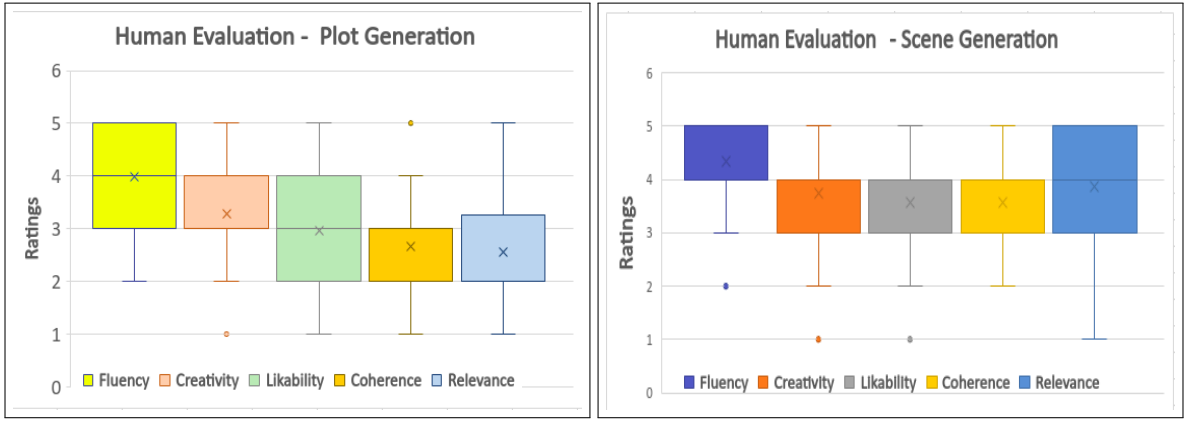
having been assigned 10 unique plots. The ratings given for the 5 features are in Figure 5. The average scores for fluency, creativity, likability, coherence and relevance are 3.98, 3.29, 2.97, 2.65 and 2.55, respectively. Fluency of almost 4 is an indicator of the power of GPT-3 as a language model. Creativity and likeability are respectable at a value of around 3.0. The low BLEU scores support the average creativity score (Table 1). Figure 5 indicates that coherence and relevance still have major room for improvement.
The MAUVE (Pillutla et al., 2021) value measures the gap between neural text and human text. We have separately calculated the MAUVE scores for 20 plots and 50 plots. The weighted average of the MAUVE scores for the two experiments is 0.48 which is reasonably good.
6.1.3. Qualitative Observations
Professional scriptwriters from our industry partner have given the following observations:
Non-annotated Hollywood Plots
• The build-up is creative and interesting, but the ending becomes incoherent.
• Some characters which are introduced in the beginning are never mentioned again.
• The output is not portraying the key points or the theme mentioned in the input.
Annotated Hollywood Plots
• The plots are much more coherent, and the endings are logical.
• There is still hallucination present (a common feature of all models).
• The longer inputs made the plots more attentive to the key points.
Annotated Hollywood Plots with Genres included
• Along with the above points, now the plots generated are more tilted towards the genre or genres of the movie the writer wants to create.
• Addition of genre gives some control over the kind of plot generated by the model.
Annotated Bollywood plots
• The outputs show incoherence in the last two paragraphs and repetition of the same characters throughout the plot.
• The flow of the plot is not fast enough, i.e., the plot does not move ahead much.
• Many of the outputs have a 1990s theme around them, where the characters are separated and then find each other later. This is due to a skewed dataset with lesser modern plots.
6.2. Scene Generation
We fine-tuned GPT-3 for scene generation with our dataset. We generated ten scenes using the models mentioned in 5.1. Figure 7 in the appendix. shows an example of a completely generated scene.
6.2.1. Human Ratings
We conducted a human evaluation on 10 scenes generated by the above model. 5 people evaluated the scenes using the Likert Scale. The ratings for the five features can be seen in Figure 5. The average scores for fluency, creativity, likability, coherence, and relevance are 4.48, 3.9, 3.48, 3.46 and 3.86, respectively. All of the values are above the neutral mark and imply that the generated scenes are close to human-written scenes.
6.2.2. Qualitative Observations
In this section, we analyze the quality of the scenes generated by the GPT-3 model. This analysis has been done by professional scriptwriters from the previously mentioned media company.
• The model produces a well-structured scene.
• It can create new characters and fabricate dialogues even when they are unimportant.
• The key points from the input can be found in the output.
• There are some lines that are repetitive.
• The output is not completely coherent.
This paper is available on arxiv under CC 4.0 DEED license.