
Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
APPENDIX A - APPENDIX TO CHAPTER 3
A.1 Adding a Backward Language Modeling Loss to GPT-Style Pretraining
Previous work (Dong et al., 2019) combines various pretraining losses, including the forward and backward language modeling losses and the masked/prefix language modeling loss. However, little work has been done to identify whether the forward and backward language modeling losses are sufficient for these pretrained models to achieve strong performance in downstream tasks. This idea is in part inspired by Electra (Clark et al., 2020) where they found having training losses at every position helps the training efficiency and we want to see whether concatenating forward and backward language modeling losses can achieve similar outcome. In addition, if we could achieve ELMo-style bidirectionality by simply manipulating the attention masks without introducing additional parameters, it could allow us to adapt the pretrained GPT checkpoints to be bidirectional by finetuning with the backward language modeling. The models could also have advantages when used for computing the probabilities of text to re-rank outputs due to its approach of achieving bidirectionality.
In experiments, we train BERT models with 128 hidden dimensions on Wikipedia using both forward and backward language modeling losses (BiDir). For baselines, we consider a BERT model trained with forward only language modeling loss (UniDir) and a BERT model trained with the masked language modeling loss (MLM). We also consider Electra and XLNet (Yang et al., 2019) of similar sizes to compare different ways to achieve bidirectionality. In particular, Electra uses a discriminative objective and XLNet uses permutation language modeling. For all these experiments, we train the models from scratch and use a batch size of 256, a learning rate of 1e-4, and 300k training steps. For evaluating downstream performance, we perform the BERT-style evaluation on the GLUE benchmark and finetune the whole model. We note that when evaluating Unidir on GLUE tasks, we use the last embedding. For BiDir, we concatenate the last and first embeddings.
We report results in Table A.1. We find that Electra shows best performance likely due to its efficient training objective. XLNet shows slightly worse performance than the MLM-trained BERT model. Interestingly, BiDir achieves better performance than UniDir on average, but it performs worse than MLM, likely due to the fact that while compared to UniDir, BiDir has an extra training signal (i.e., backward language modeling loss), it still falls behind the MLM as the models never use full attention and full attention is a superior choice than causal attention for GLUE tasks.
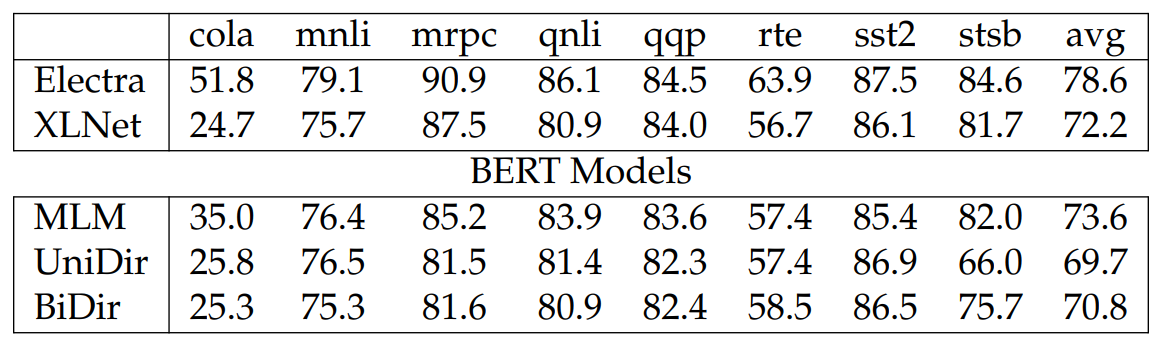

We investigate the effect of using full attention on UniDir and BiDir in Table A.2. Generally using different attention patterns during test time leads to much worse performance. However, it is interesting to see that BiDir models still maintain the improvement with the full attention pattern, showing that the models learn to better leverage information from both sides than UniDir.
A.2 Details about Downstream Evaluation Tasks for ALBERT
GLUE. GLUE is comprised of 9 tasks, namely Corpus of Linguistic Acceptability (CoLA; Warstadt et al., 2019), Stanford Sentiment Treebank (SST; Socher et al., 2013), Microsoft Research Paraphrase Corpus (MRPC; Dolan and Brockett, 2005), Semantic Textual Similarity Benchmark (STS; Cer et al., 2017), Quora Question Pairs (QQP; Iyer et al., 2017), Multi-Genre NLI (MNLI; Williams et al., 2018), Question NLI (QNLI; Rajpurkar et al., 2016), Recognizing Textual Entailment (RTE; Dagan et al., 2005; Bar-Haim et al., 2006; Giampiccolo et al., 2007; Bentivogli et al., 2009) and Winograd NLI (WNLI; Levesque et al., 2012). It focuses on evaluating model capabilities for natural language understanding. When reporting MNLI results, we only report the “match” condition (MNLI-m). We follow the finetuning procedures from prior work (Devlin et al., 2019; Liu et al., 2019; Yang et al., 2019) and report the held-out test set performance obtained from GLUE submissions. For test set submissions, we perform task-specific modifications for WNLI and QNLI as described by Liu et al. (2019) and Yang et al. (2019).
SQuAD. SQuAD is an extractive question answering dataset built from Wikipedia. The answers are segments from the context paragraphs and the task is to predict answer spans. We evaluate our models on two versions of SQuAD: v1.1 and v2.0. SQuAD v1.1 has 100,000 human-annotated question/answer pairs. SQuAD v2.0 additionally introduced 50,000 unanswerable questions. For SQuAD v1.1, we use the same training procedure as BERT, whereas for SQuAD v2.0, models are jointly trained with a span extraction loss and an additional classifier for predicting answerability (Yang et al., 2019; Liu et al., 2019). We report both development set and test set performance.
RACE. RACE is a large-scale dataset for multi-choice reading comprehension, collected from English examinations in China with nearly 100,000 questions. Each instance in RACE has 4 candidate answers. Following prior work (Yang et al., 2019; Liu et al., 2019), we use the concatenation of the passage, question, and each candidate answer as the input to models. Then, we use the representations from the [CLS] token for predicting the probability of each answer. The dataset consists of two domains: middle school and high school. We train our models on both domains and report accuracies on both the development set and test set.
A.3 Additional Details for LPP and Classification Tasks
The label strings we used for LPP are as follows: Yes and No, Y and N, True and False, and T and F. We randomly choose from Yes, Y, True, and T as the label string for the positive label and use the other one in the selected pair as the negative label.
The label strings we used for the binary classification task are the same as the classification LPP task. For the three-way classification task, we use the following label strings: Positive and Negative and Neutral, True and False and Neither, T and F and N, Yes and No and Unknown, Y and N and U.
List of Function Words for LPP. We used the following function words for identifying the last phrase: the, a, an, for, including, and, in, is, are, were, was, neither, or, nor, be, at, in, on, by, to, would, will, before, after, of, about, from, excluding, except, during, under, above, then, into, onto, should, shall, must, may, might, than, with, using, can, could, about, as, from, within, without, have, had, been.
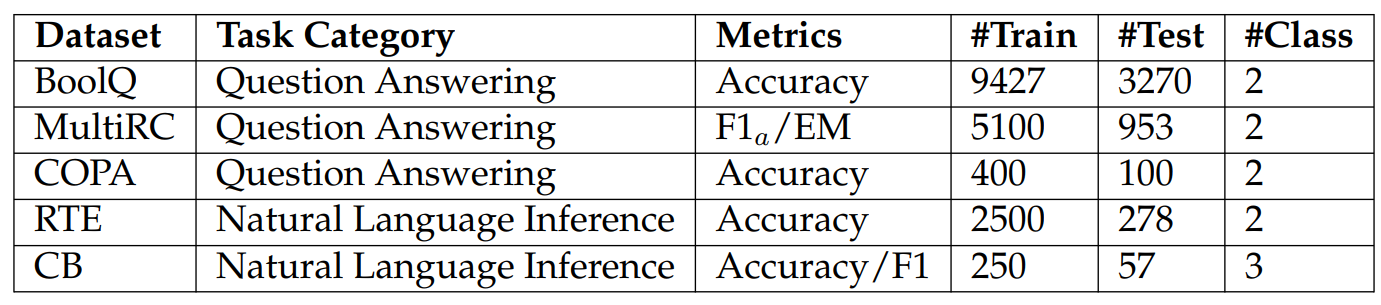
A.4 Dataset Statistics for SuperGLUE and Natural-Instructions
We report dataset statistics for SuperGLUE and Natural-Instructions in Table A.3 and Table A.4, respectively.
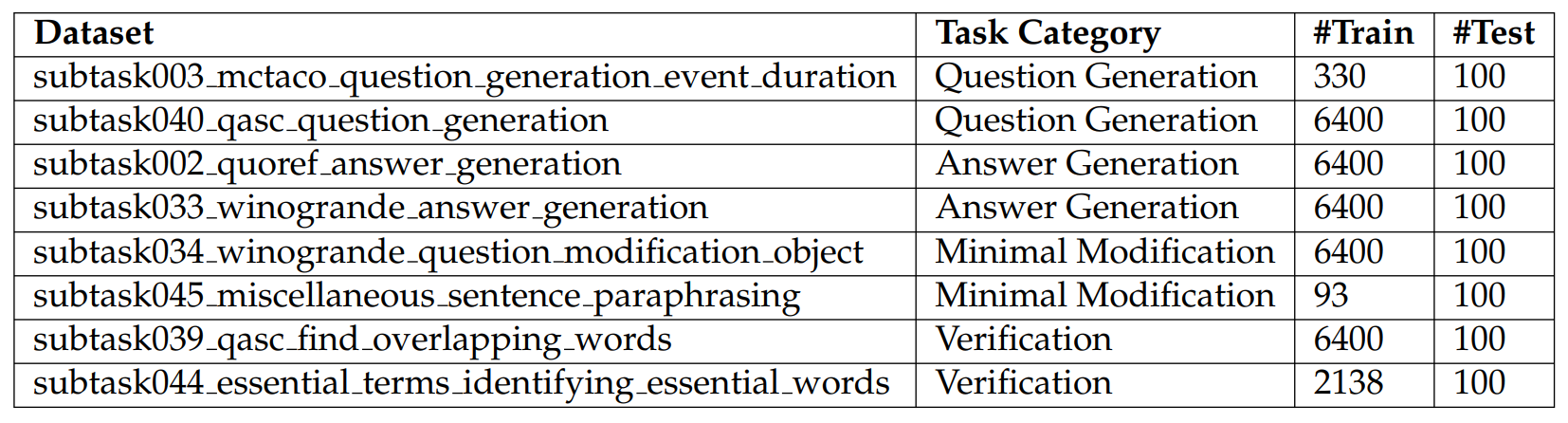
A.4.1 More Details about Natural-Instructions
Dataset Sources. CosmosQA (Huang et al., 2019), DROP (Dua et al., 2019), EssentialTerms (Khashabi et al., 2017), MCTACO (Zhou et al., 2019), MultiRC (Khashabi et al., 2018), QASC (Khot et al., 2020), Quoref (Dasigi et al., 2019), ROPES (Lee et al., 2021) and Winogrande (Sakaguchi et al., 2020).
Training Datasets. We used the following 8 datasets when training models in the cross-task setting: subtask026 drop question generation, subtask060 ropes question generation, subtask028 drop answer generation, subtask047 misc answering science questions, subtask061 ropes answer generation, subtask059 ropes story generation, subtask027 drop answer tsubtask046 miscellaenous question typing.
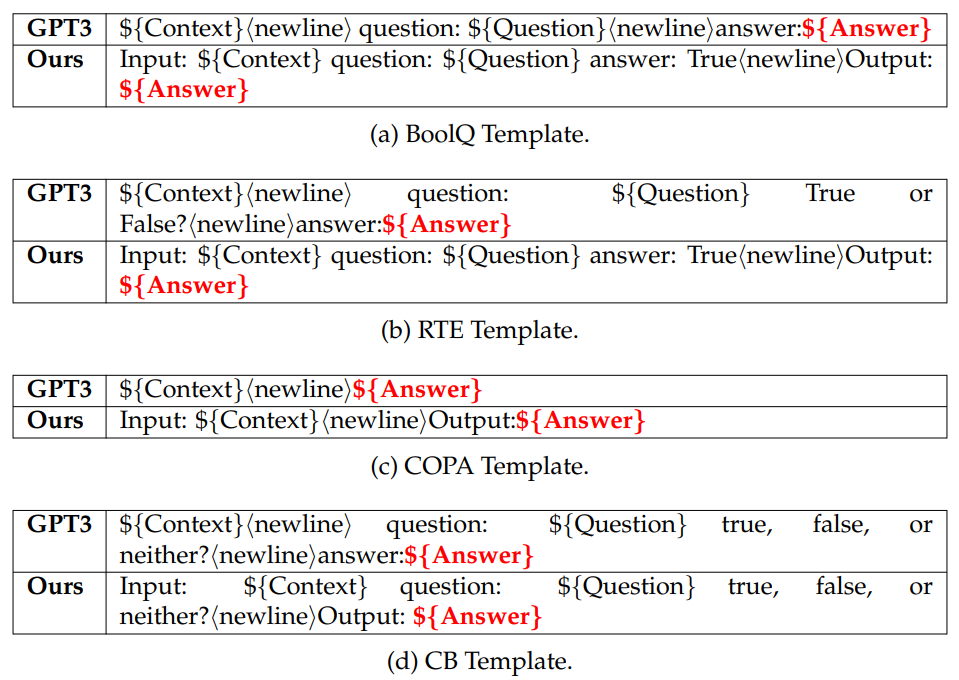
A.5 Templates for SuperGLUE
We show the SuperGLUE templates in Table A.5.
This paper is available on arxiv under CC 4.0 license.