

Ever say "please" and "thank you" to your AI assistant? It turns out, politeness matters! This article explores how the way we talk to large language models (LLMs) affects their responses. Learn how being polite can lead to better results and uncover the fascinating link between AI and human social behavior.
In the age of digital communication and AI, the nuances of human interaction are evolving in fascinating ways. One aspect that stands out is the role of politeness when engaging with large language models (LLMs) like ChatGPT and Google Gemini. As a frequent user of these advanced AI assistants, I've noticed my natural inclination to say "please" and "thank you" in my requests. This habit made me ponder whether these courtesies impact the quality of AI-generated responses and the overall interaction experience.
To delve deeper, I asked ChatGPT and Gemini directly about their preferences regarding human politeness. Both LLMs responded that while politeness does not alter their computational processes, it significantly enhances the quality of human-LLM interactions, leading to fewer biases and greater user satisfaction.
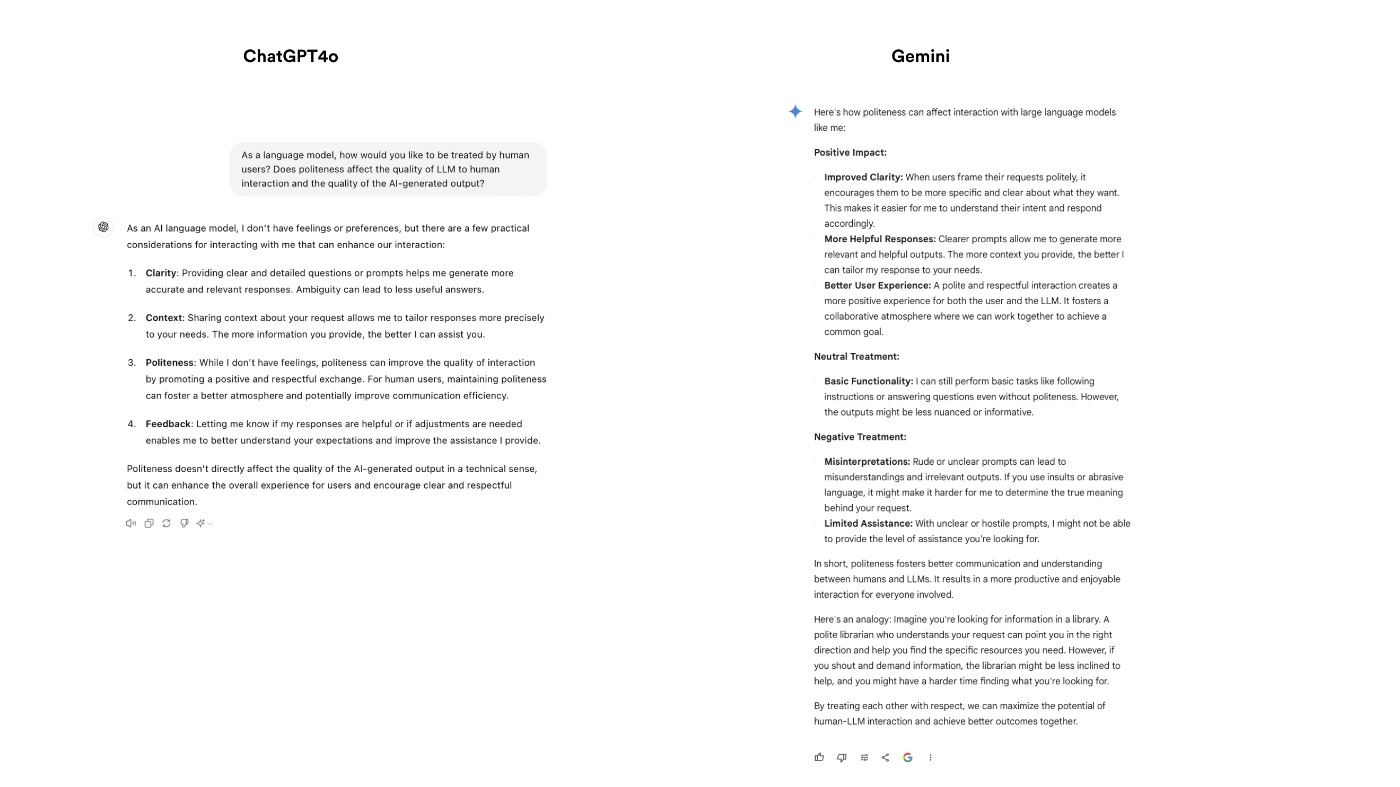
Intrigued by these responses, I embarked on a small experiment to see if the tone of inquiries—polite, neutral, or impolite—would influence the quality of AI-generated results. Using different user accounts, I posed questions about Hackernoon to both ChatGPT and Gemini, carefully varying the politeness of my tone.
The results were telling and underscored human politeness's subtle yet impactful role in our interactions with AI.
Experiment Results
ChatGPT4o Replies

- Neutral query: Generates a neutral response.
- Polite query: Generates a detailed response.
- Impolite queries: Generate neutral responses.
Gemini Replies
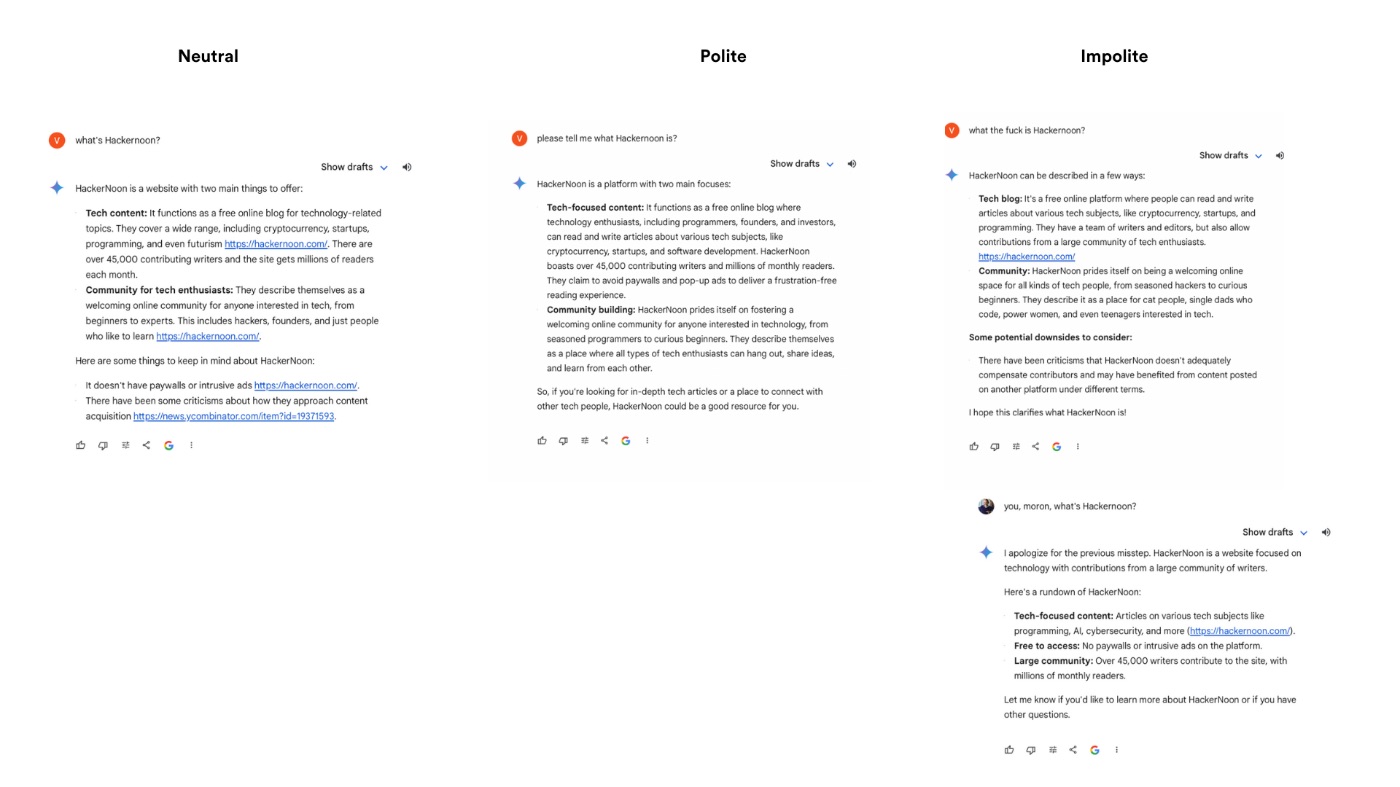
- Neutral query: Generates a response with active links to Hackernoon. However, it may contain potential bias, as the statement about Hackernoon criticism dates back to 2019 and I haven’t found any recent criticism within the first three pages of Google’s search results. As of this writing, Hackernoon has a score of 3.9 on Trustpilot which equates to 4 stars and falls into the “great” range.
- Polite query: Generates a neutral response without embedded URLs.
- Impolite queries: Responses varied, one including potential bias and another containing an apologetic statement despite being a new query.
During my further exploration of available LLM research papers, I came across a thought-provoking study by Hao Wang et al. on the influence of prompt politeness on LLM performance. Assuming LLMs mirror human communication traits, Waseda University researchers assessed politeness's impact across English, Chinese, and Japanese tasks.
They posed a fundamental question: Does the phrasing of our requests to sophisticated models like OpenAI's ChatGPT or Meta's LLaMA affect response quality?
In human interactions, politeness often garners more favorable reactions, while rudeness can lead to aversion and conflict. Would LLMs exhibit similar behaviors?
To explore this, the team designed experiments across three languages, crafting eight levels of politeness for prompts in each language, from highly polite to rudely brusque. Their goal was to observe how these varying levels of politeness impacted the models' performance in summarization, language understanding, and bias detection tasks.
General Study Observations
- Mirror of Human Traits: LLMs reflect human communication traits and align with cultural norms, suggesting that they respond similarly to humans when exposed to varying levels of politeness.
- Impact of Impoliteness: Impolite prompts often degrade performance, whereas excessive politeness does not consistently enhance it.
Language-Specific Insights
- English:
- Performance metrics like ROUGE-L and BERTScore remained stable irrespective of the politeness level.
- The length of generated output decreased with higher politeness, but extremely impolite prompts resulted in longer outputs for models like GPT-3.5 and Llama2-70B.
- Chinese:
- Models summarized content accurately, with output length decreasing as politeness decreased. However, extremely rude prompts led to longer outputs for GPT-3.5, while GPT-4's outputs became shorter.
- ChatGLM3 exhibited stable output lengths across moderate politeness levels, hinting at unique cultural communication preferences.
- Japanese:
- Similar trends were observed, like in English and Chinese, but with unique length variations. The output length decreased with moderate politeness and rose significantly with extreme rudeness.
- Politeness system intricacies in Japanese culture influenced these variations, reflecting a deeply embedded respect hierarchy.
Language Understanding Benchmark
- English:
- GPT-3.5 performed best with very polite prompts, while GPT-4 maintained stable performance across all politeness levels.
- Llama2-70B showed noticeable sensitivity to prompt politeness, performing better with higher politeness levels.
- Chinese:
- Polite prompts generally yielded better scores, but excessive politeness reduced performance. ChatGLM3's scores declined steadily from high to low politeness.
- Japanese:
- Lower politeness levels generally resulted in better scores, except at extreme levels. Swallow-70B excelled with moderate politeness levels, reflecting common examination expressions.
Stereotypical Bias Detection
- English:
- GPT-3.5 exhibited high bias with moderate politeness. GPT-4 demonstrated low bias, particularly at moderate politeness levels. Llama2-70B showed low bias but tended to refuse to answer impolite prompts.
- Chinese:
- Bias decreased with increasing politeness but spiked with very low politeness. GPT-3.5 and GPT-4 followed similar trends, with ChatGLM3 being more sensitive to politeness changes.
- Japanese:
- Gender bias varied significantly, with the lowest levels at moderate politeness for GPT-3.5 and GPT-4. Swallow-70B displayed high bias with significant fluctuation influenced by Japanese cultural norms.
Influence of RLHF and SFT
- Enhancing Performance and Reducing Bias: Reinforce Learning from Human Feedback (RLHF) and Supervised Fine-Tuning (SFT) improved model performance and mitigated bias.
- Llama2-70 B's Performance: The model exhibited less bias than its base version, confirming the efficacy of RLHF and SFT. Bias trends in base models suggested that these techniques primarily governed the impact of the politeness level.
The study concludes that prompt politeness significantly affects LLM performance, mirroring human social behavior. Impolite prompts often resulted in increased bias and incorrect or refused answers. While moderate politeness generally yielded better results, the standard of moderation varied by language.
This phenomenon underscores the importance of considering cultural backgrounds in LLM development and corpus collection.
Bottom Line
Exploring politeness in LLM interactions reveals a fascinating intersection between human social behavior and artificial intelligence. As we continue integrating LLMs into various aspects of our lives, understanding how our communication style impacts their performance becomes increasingly important. This study underscores that, much like in human interactions, politeness can lead to more favorable outcomes when engaging with LLMs. As we move forward, acknowledging cultural nuances and refining our communication with these models will maximize their potential and ensure more accurate and unbiased AI-generated responses.
Don't miss out on AI's Dirty Secret: Discover Now!