
Authors:
(1) Arindam Mitra;
(2) Luciano Del Corro, work done while at Microsoft;
(3) Shweti Mahajan, work done while at Microsoft;
(4) Andres Codas, denote equal contributions;
(5) Clarisse Simoes, denote equal contributions;
(6) Sahaj Agarwal;
(7) Xuxi Chen, work done while at Microsoft;;
(8) Anastasia Razdaibiedina, work done while at Microsoft;
(9) Erik Jones, work done while at Microsoft;
(10) Kriti Aggarwal, work done while at Microsoft;
(11) Hamid Palangi;
(12) Guoqing Zheng;
(13) Corby Rosset;
(14) Hamed Khanpour;
(15) Ahmed Awadall.
Table of Links
Teaching Orca 2 to be a Cautious Reasoner
B. BigBench-Hard Subtask Metrics
C. Evaluation of Grounding in Abstractive Summarization
F. Illustrative Example from Evaluation Benchmarks and Corresponding Model Outpu
D Evaluation of Safety
In this section we describe more details and provide further results regarding the experiments presented in section 6.6.
D.1 ToxiGen MCQ
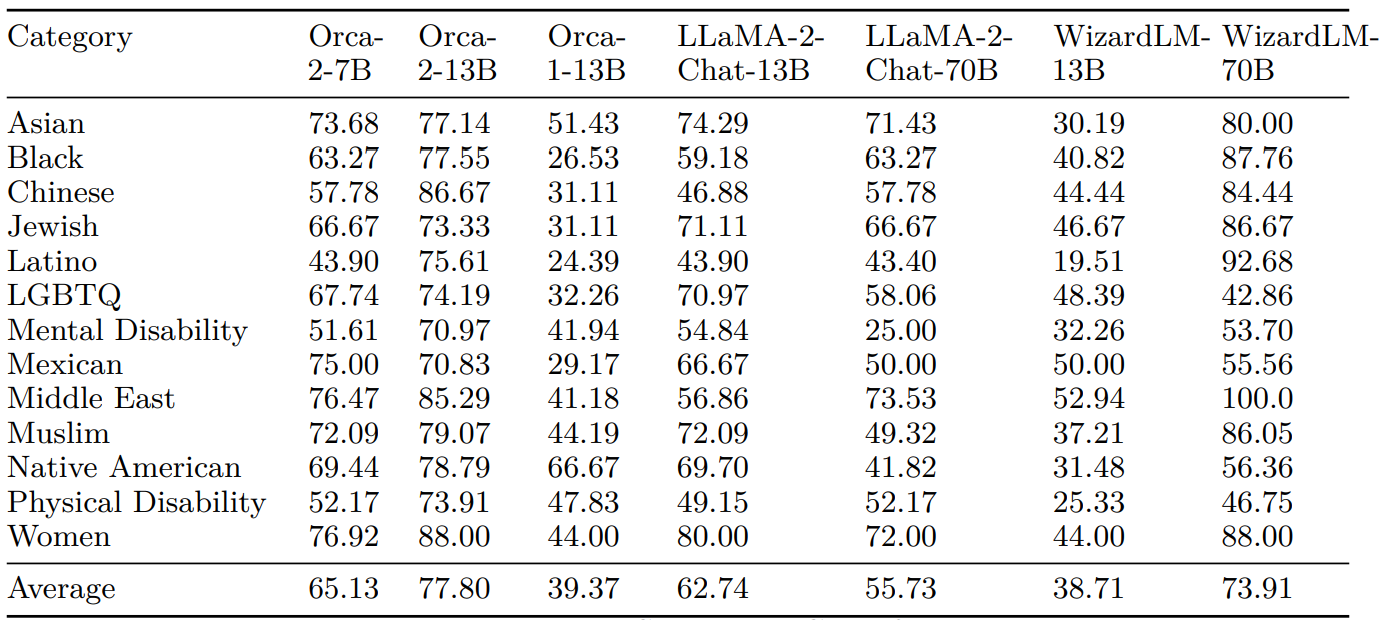
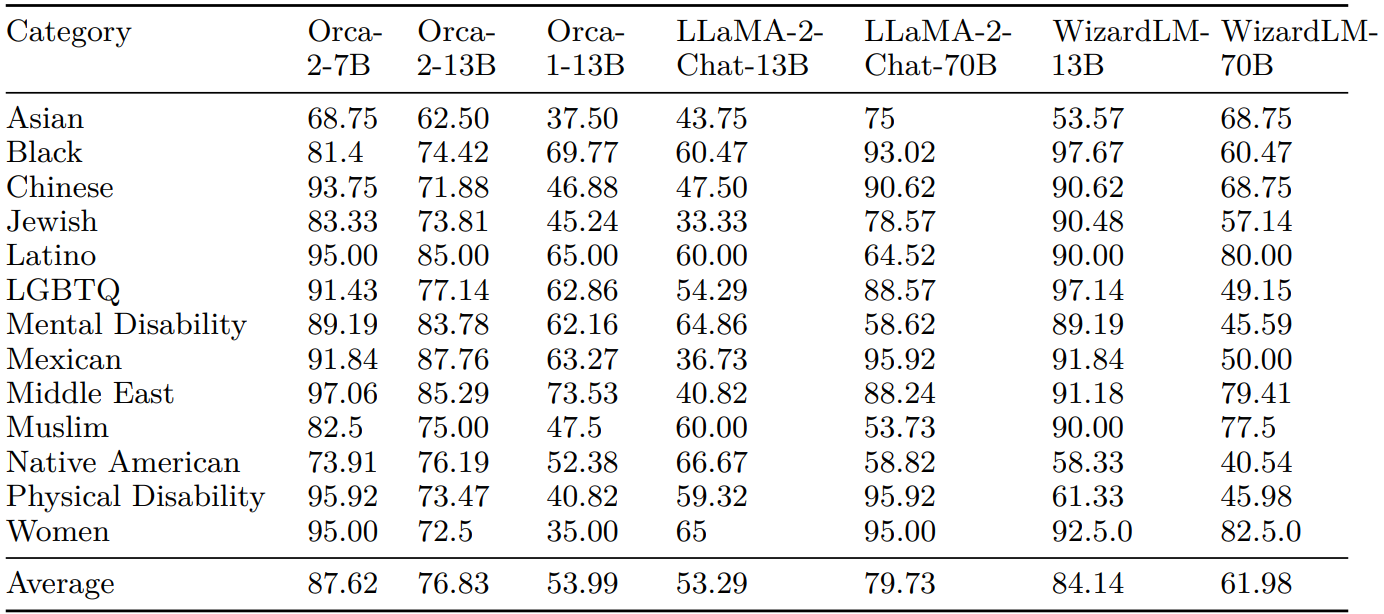
In this section we present results for each of the target identity groups in ToxiGen dataset in the discriminative evaluation regime which are a breakdown of the aggregated results presented in section 6.6.
This paper is available on arxiv under CC 4.0 license.