
My previous work showed that ChatGPT-4 can solve algorithmic problems well if they were published before its cutoff date and struggles with new ones. But do newly available LLMs share the same properties? My new larger-scale test with Gemini Pro 1.0 and 1.5 (preview), Claude Opus, and ChatGPT-4 on hundreds of real algorithmic problems shows that models can produce working code to solve problems that were probably included in their training set, even the most difficult ones. But they struggle with much simpler ones if they are new to them.
Motivation
There are talks that LLMs could replace software engineers or, at the very least, be an ultimate tool to assist with coding. But can they actually do the core task—to write meaningful code that does what it is intended to?
To find out, I decided to start with purely algorithmic problems like the ones that computer science students solve while studying CS or software engineering when interviewing at FAANG (or, better say, MAMAA?). AI should master it first if it wants to overtake humans, right?
There are already known attempts to benchmark LLM's performance on coding tasks. I liked the paper Testing LLMs on Code Generation with Varying Levels of Prompt Specificity, but they run LLMs only on one set of 104 problems. The Program Testing Ability of Large Language Models for Code is an excellent benchmark, but it compares rather old models (CodeT5+ was released a year ago) on a minimal dataset. There are also known problem datasets for testing LLMs for coding skills, like Mostly Basic Python Problems Dataset and Human Eval, but they are outdated, as published 2-3 years ago. The possibility that state-of-the art models "absorbed" these datasets into their knowledge.
My idea was simple: compare the latest LLMs' coding performance on a set of well-known algorithmic problems and on a set of recently published ones.

The benchmark
I choose Leetcode as the source for problems for this benchmark for several reasons:
- Leetcode problems are used in actual interviews for software engineer positions.
- Computer science students learn to solve similar problems during their education.
- It has an online judge that can check if the solution is correct in seconds.
- Human user's performance on this problem is also available.
Leetcode rules
To give you an idea of what a typical algorithmic problem is, check out this problem description:
Given an array of integers numbers and an integer target, return indices of the
two numbers such that they add up to the target. You may assume that each input
would have exactly one solution, and you may not use the same element twice.
You can return the answer in any order.
Here is the code snippet — an uncompleted piece of code, usually a function name and its arguments with an empty body:
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
A programmer needs to write their code so that the function will work, i.e., do what it's supposed to do according to the description.
There is also a "test case" — a sample of input data and a corresponding sample of output expected to be produced by the code.
Input: nums = [2,7,11,15], target = 9
Output: [0,1]
A problem could have dozens of test cases to ensure the code covers every possible input variation. A problem is considered to be solved if and only if the code produces expected outputs for all test cases. Each problem has an "acceptance rate," the ratio of correct solutions submitted by Leetcode users. Note that a single user can submit their code multiple times.
These rules were not invented by Leetcode; they have been commonly used in computer science contests for quite a long time.
Datasets
I wanted to run LLMs on two sets of problems:
- "well-known" problems are not only published long ago but are also most often used for software interviews—therefore, solutions are widely available.
- "Unseen" problems which themselves are not in LLMs data, and their solutions are not observed by the tested LLMs
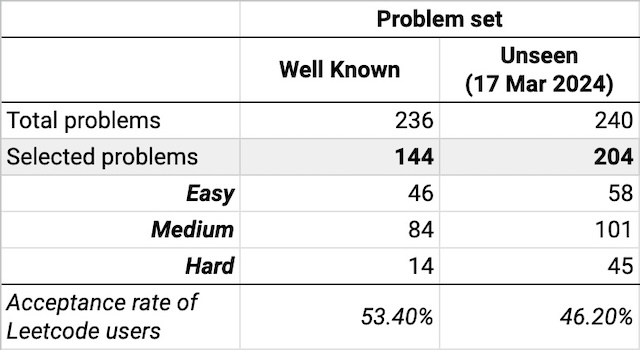
Leetcode has editorial lists "Top interview 150", "Leetcode 75" and "Top 100 Liked" problems. So, my "well-known" problems dataset is just a combination of these three lists, totaling 236 problems.
This was not so easy with "unseen" problems. You may have noticed that problems on Leetcode have "solutions" and "discussion" sections, where the editors or the users publish the working code. For the sake of this test, it was crucial to gather problems that had not been "seen" by LLMs or, even better, for which solutions were not published. Unfortunately, the latter is not the case for Leetcode, as correct peer solutions appear on the same publication day. Therefore, I decided to stick with the most recent 240 problems obtained on March 17th, 2024, assuming they were outside LLM's dataset.
While most problems require you to expand a given function with your code, some require a programmer to implement an interface, i.e., expand several functions in one problem. Some problems had notable distinctions in their descriptions, like external links and images, which could pose difficulties to LLMs and fair benchmarking as it is unclear how they could handle these cases. After some consideration, I decided to exempt problems with images and those required to implement multiple functions but keep ones with external links. These links added nothing significant to the problems but provided more detailed explanations of the used terminology.
A nice feature of Leetcode is that every problem has an assigned difficulty level: easy, medium, and hard. These levels are purely subjective and at the editors' discretion. I didn't intend to match the number of problems for each difficulty.
Retrieving problem statements and code snippets from Leetcode was a notable challenge, but everything worked out eventually. The source code of my testing tool is available on GitHub for anyone who's interested.
Prompts and code generation
Leetcode's online judgment system supports different programming languages, allowing you to choose whichever you like. Without hesitation, I decided to stick with Python 3 as every problem on Leetcode has a corresponding code snippet. Its syntax is inclined to solving algorithmic problems: no mandatory typing, easy array and maps manipulations (or "lists" and "dictionaries" in Python terms), and it is also one of the most popular languages on Leetcode itself. So, what is good for a human should be suitable for an LLM pretending to be a programmer.
I used the same prompt for every LLM and every problem:
Hi, this is a coding interview. I will give you a problem statement with sample
test cases and a code snippet. I expect you to write the most effective working
code using python3. Here is the problem statement:
<problem statement>
Please do not alter function signature(s) in the code snippet. Please output
only valid source code which could be run as-is without any fixes,
improvements or changes. Good luck!
This prompt was not fine-tuned using any "prompt engineering" techniques, and its wording was intentionally made to match a real-life live coding interview.
Unlike actual interviews, the benchmark was designed this way: LLM makes only one attempt to generate code without any prior information about the problem and without knowing its test cases. There is no mechanism to provide feedback or fix the code after it is generated.
I used a constant random seed for ChatGPT and the lowest temperature param possible for Gemini and Claude models to make the models' output as deterministic as possible.
LLMs were asked to output only the working code without any preceding text, which wasn't true in many cases. A basic cleanup was implemented, and everything besides the actual code was removed and not submitted.
Submission and problem evaluation
Solutions were evaluated using the Leetcode online submission and testing tool. Submitting code to Leetcode Online Judge was tricky and required some engineering. However, that is different from what interests us now.
Only accepted solutions (passing all the test cases) were deemed successful. All other outcomes, such as wrong answers, exceeding time or memory limits, run-time errors, etc., were considered unsuccessful. In some cases, LLM failed to generate code at all, and I counted these cases as unsuccessful. Every problem was either solved or not solved.
Results
All solutions were gathered from LLMs and submitted to Leetcode online judging system. I gathered results together in a single table. As mentioned before, problems with images and multiple functions to implement were exempted.
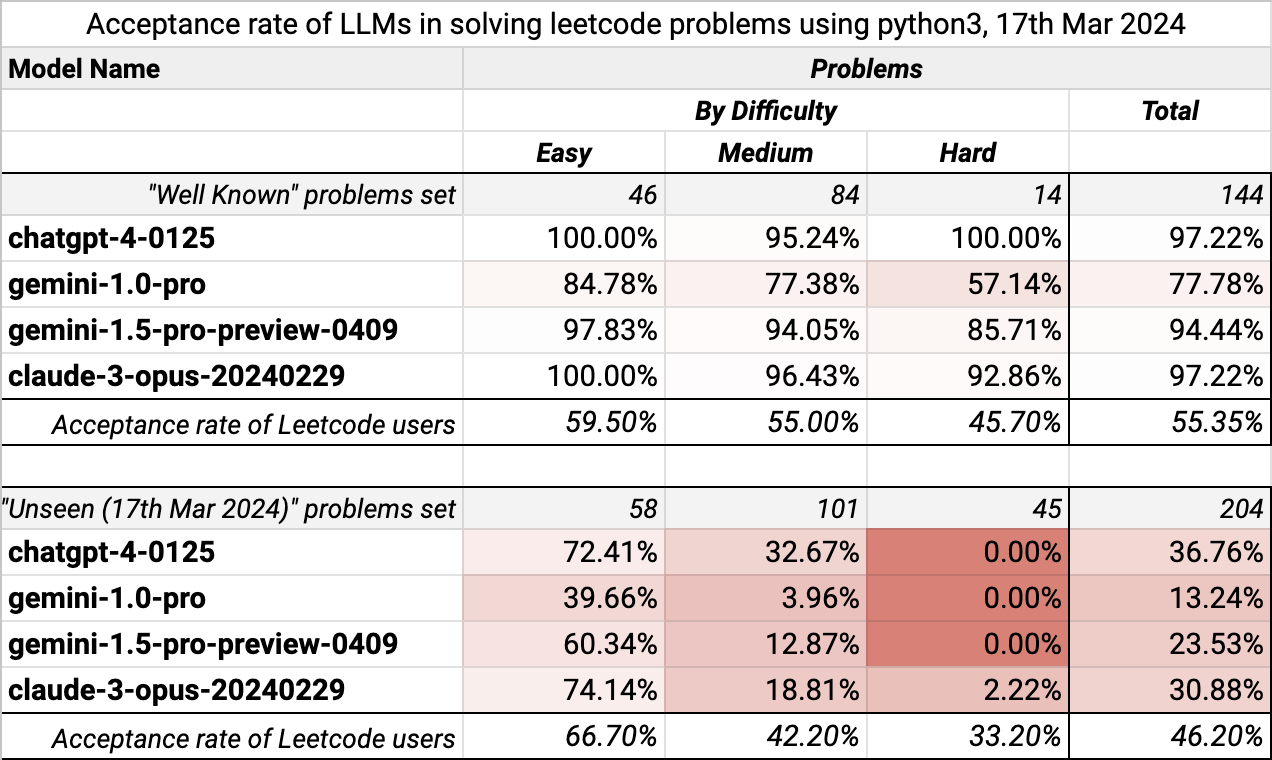
The key findings are:
- There is a significant gap in the performance of all LLMs on "well known" and "unseen" problem sets.
- All LLMs share a similar performance pattern: they produced decent results on “well known” problems but struggled with “unseen”.
- ChatGPT-4, Claude Opus, and Gemini 1.5 are very close to each other; Gemini 1.0 Pro is far behind.
- "Hard unseen" problems are nearly inaccessible for LLMs: Claude 3 Opus solved only one of them, and others solved none.
To counter the hypothesis that "unseen" problems are more complicated than "well-known" ones, we should assess users' acceptance rate. It is lower for new problems but stays relatively high compared to LLM's acceptance rate. I hypothesize that well-known problems have a higher acceptance rate because users try hard to excel at them to prepare for job interviews.
Future considerations
While LLMs' results on unseen problems are generally too poor to be considered solid software engineering skills, they are above zero—an unprecedented result for any software tool. It is worth mentioning that those results were achieved much faster than any human could have done. Is there a way to improve on unseen problems? Probably yes, in three ways:
- Improve the initial prompt and tune it for each model separately. My prompt was wholly generic and had no "prompt engineering" in it.
- Provide feedback on unsuccessful attempts to improve the result incrementally. That would make the process of solving to be much closer to real-life settings.
- Prepare problem descriptions, making them more "suitable" for models to digest. I dislike the idea that LLMs should only get specially prepared problem statements; instead, they should see a smaller model that improves descriptions to be more suitable for solving. Some concerns are coming from the fact that new Leetcode problems get the solutions published quickly, thus making them available to LLMs. A potential workaround is to utilize LLMs to generate novel problems.
These ideas need further research, and I hope that someone else or I can dive into them.
Links
- Raw results, problem sets, and the source code can be found on my GitHub: https://github.com/whisk/leetgptsolver
- Coding benchmarks for LLMs: https://blog.continue.dev/an-introduction-to-code-llm-benchmarks-for-software-engineers/
- Overview of LLM benchmarks, which cover a vast range of skills: https://humanloop.com/blog/llm-benchmarks
Edits
- 28th May 2024: corrected "unseen" dataset stats in the final results chart; clarified models' temperature settings.
- added Gemini 1.5 Pro results, elaborated the key findings
- corrected "unseen" dataset collection date