
Prologue
We are only talking about time complexity in this article - deliberately.
For space complexity, refer to my article on 1-bit transformers, available here:
https://hackernoon.com/why-1-bit-transformers-will-change-the-world?embedable=true
Introduction
We are racing forward into the future as far as Generative AI technology is concerned and the algorithms behind Large language Models are no exception. In this article, we are going to cover three of the most exciting developments in the field of generative AI recently, and talk about them in detail. One of them has also achieved the optimal time complexity to run a large language model algorithm. In other words, a recent development has become the most optimally fastest LLM transformer algorithm possible - it is, by our current models, not possible to go faster than that as far as asymptotic time complexity is concerned, except by constant time optimizations. Because we are dealing with hundreds of billions of parameters, the constants’ speed-up can be rather large! I hope you’re as excited as I am because this will be an exciting ride!
The Incumbent Algorithm - the Attention-Based Transformer
Everyone is familiar with the seminal 2017 Attention is all you need paper, but I am going to summarize it anyway so that newcomers will have a clearer picture of what we’re talking about.
This is the link to the research paper:
https://arxiv.org/abs/1706.03762?embedable=true
From the paper introduction:
Recurrent neural networks, long short-term memory and gated recurrent neural networks in particular, have been firmly established as state of the art approaches in sequence modeling and transduction problems such as language modeling and machine translation.
Numerous efforts have since continued to push the boundaries of recurrent language models and encoder-decoder architectures.
Recurrent models typically factor computation along the symbol positions of the input and output sequences.
Aligning the positions to steps in computation time, they generate a sequence of hidden states ℎ𝑡, as a function of the previous hidden state ℎ𝑡−1 and the input for position 𝑡.
This inherently sequential nature precludes parallelization within training examples, which becomes critical at longer sequence lengths, as memory constraints limit batching across examples.
Recent work has achieved significant improvements in computational efficiency through factorization tricks and conditional computation, while also improving model performance in case of the latter.
The fundamental constraint of sequential computation, however, remains.
Attention mechanisms have become an integral part of compelling sequence modeling and transduction models in various tasks, allowing modeling of dependencies without regard to their distance in the input or output sequences.
In all but a few cases, however, such attention mechanisms are used in conjunction with a recurrent network.
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output.
The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.

And as we know, the GPT-1, GPT-2, GPT-3 and the GPT 3.5 transformers soon revolutionized generative AI forever. Suddenly machines could speak seemingly human English.
This was the classic diagram which dominated articles and research news bulletins for the next two years:
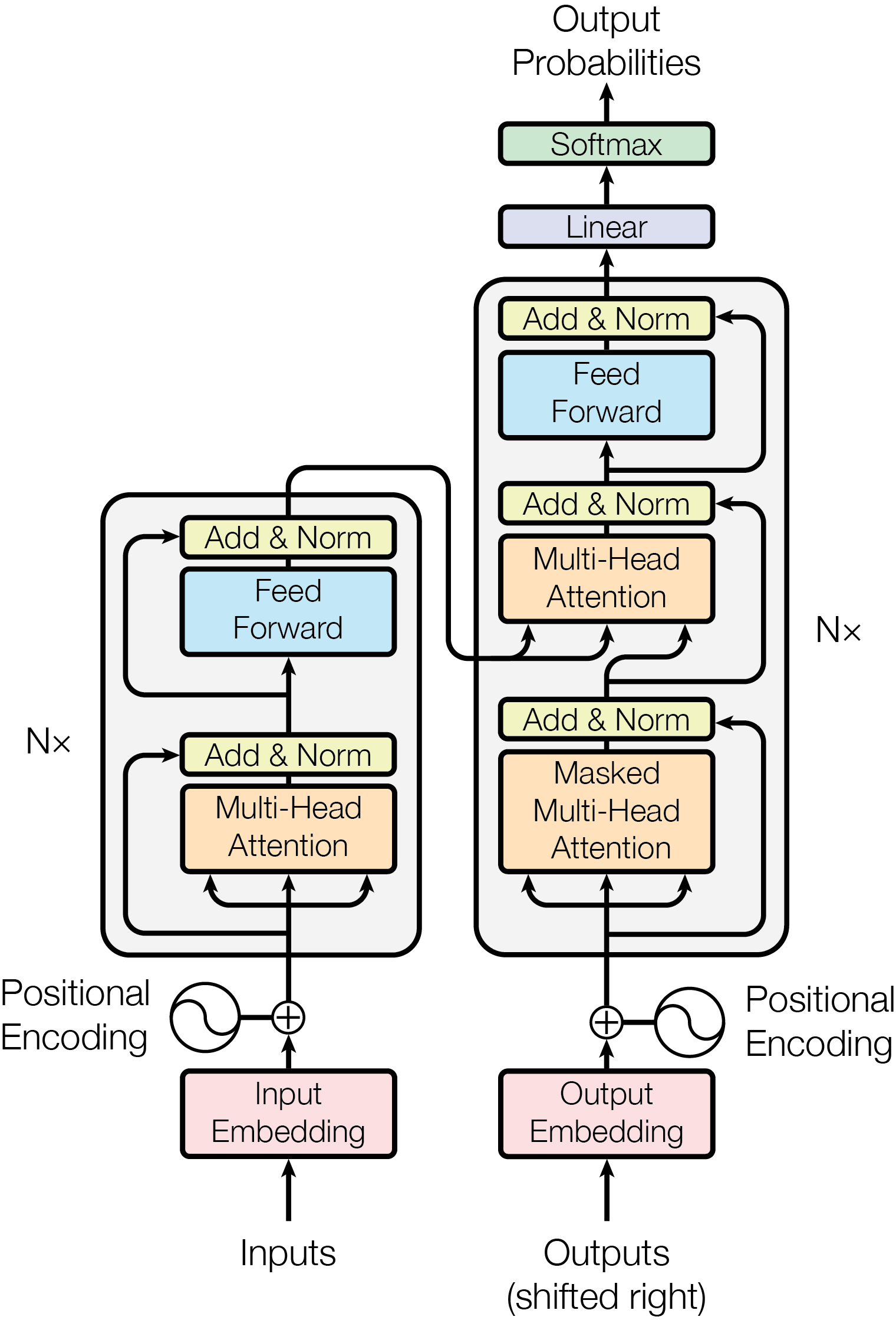
Then GPT-4 came out - and life would never be the same again.
We had crossed a tipping point.
But, these transformers were expensive, slow to train, and difficult to deploy because of their extremely high operating costs.
The time complexity of the Transformer algorithm was quadratic, or O(n*n) where n was the number of input parameters.
For a standard transformer model with 𝐿 layers, the time complexity of the inference algorithm is 𝑂(L*n*n*d) where L was the number of layers, n the number of input tokens, and d the depth of the transformer.
This seemed to be the state of the art - for a while.
Quantization was introduced in another paper as early as 2021, and that seemed to be the next state-of-the-art mechanism (See the Prologue section).
But soon we were about to have another contender.
Welcome to the Mamba Algorithm
This was the relevant research paper:
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
https://arxiv.org/abs/2312.00752?embedable=true
From the research paper abstract:
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module.
Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language.
We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements.
First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token.
Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode.
We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba).
Mamba enjoys fast inference (5× higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences.
As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics.
On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.

Suddenly we had a new competitor in town!
The main advantages of the Mamba- transformer algorithm were:
- Hybrid Architecture:
- Mamba combined Transformer and Mamba layers, allowing for improved performance and higher throughput while maintaining a manageable memory footprint.
- Challenges Addressed:
- Memory and Compute Efficiency: Mamba addressed the high memory and compute requirements of Transformers, especially for long contexts.
- Summary State: Unlike Transformers, Mamba provided a single summary state, enabling faster inference.
- Architecture Details:
- Transformer Layers: Mamba incorporated Transformer layers.
- Mamba Layers: Mamba introduces state-space modeling (SSM) layers, which efficiently handled long contexts.
- Mixture-of-Experts (MoE): Mamba uses MoE layers to increase model capacity without significantly increasing compute requirements.
- Performance:
- Mamba performed comparably to existing models like Mixtral-8x7B and Llama-2 70B, while supporting context lengths up to 256K tokens.
- Efficiency: Mamba’s throughput was 3x that of Mixtral-8x7B for long contexts, and it fitted in a single GPU even with large contexts.
The Mamba architecture represents a significant advancement in large language models, combining the strengths of both Transformer and SSM approaches.
However, as testing continued, it was found that the Mamba algorithm was not a suitable contender for all use-cases.
In particular, the Mamba algorithm failed miserably when presented with the IMDB dataset.
However the architecture was still state-of-the-art, and it was found to be hugely useful with vision use cases.
You can see an implementation in Python here:
https://github.com/alxndrTL/mamba.py?embedable=true
And this is an excellent explanation of the Mamba algorithm with the theory also provided.
And here is the standard Mamba implementation in PyPI:
https://pypi.org/project/mambatransformer/?embedable=true
The Mamba algorithm had its day and is still a highly active area of research. A successor soon came out, but we’ll save the best for last.
We’ll move on to the next contender - the xLSTM algorithm
The xLSTM Algorithm
You can refer to the research paper here:
xLSTM: Extended Long Short-Term Memory - arXiv.
https://arxiv.org/abs/2405.04517?embedable=true
From the research paper abstract:
In the 1990s, the constant error carousel and gating were introduced as the central ideas of the Long Short-Term Memory (LSTM).
Since then, LSTMs have stood the test of time and contributed to numerous deep learning success stories, in particular they constituted the first Large Language Models (LLMs).
However, the advent of the Transformer technology with parallelizable self-attention at its core marked the dawn of a new era, outpacing LSTMs at scale.
We now raise a simple question: How far do we get in language modeling when scaling LSTMs to billions of parameters, leveraging the latest techniques from modern LLMs, but mitigating known limitations of LSTMs?
Firstly, we introduce exponential gating with appropriate normalization and stabilization techniques.
Secondly, we modify the LSTM memory structure, obtaining:
(i) sLSTM with a scalar memory, a scalar update, and new memory mixing,
(ii) mLSTM that is fully parallelizable with a matrix memory and a covariance update rule.
Integrating these LSTM extensions into residual block backbones yields xLSTM blocks that are then residually stacked into xLSTM architectures.
Exponential gating and modified memory structures boost xLSTM capabilities to perform favorably when compared to state-of-the-art Transformers and State Space Models, both in performance and scaling.

The Long Short-Term Memory (LSTM) Algorithm was highly useful in its day and had its fair share of successes.
The xLSTM used the same model but in an entirely different architecture.
This was the main innovation, summarized in this diagram in the research paper:
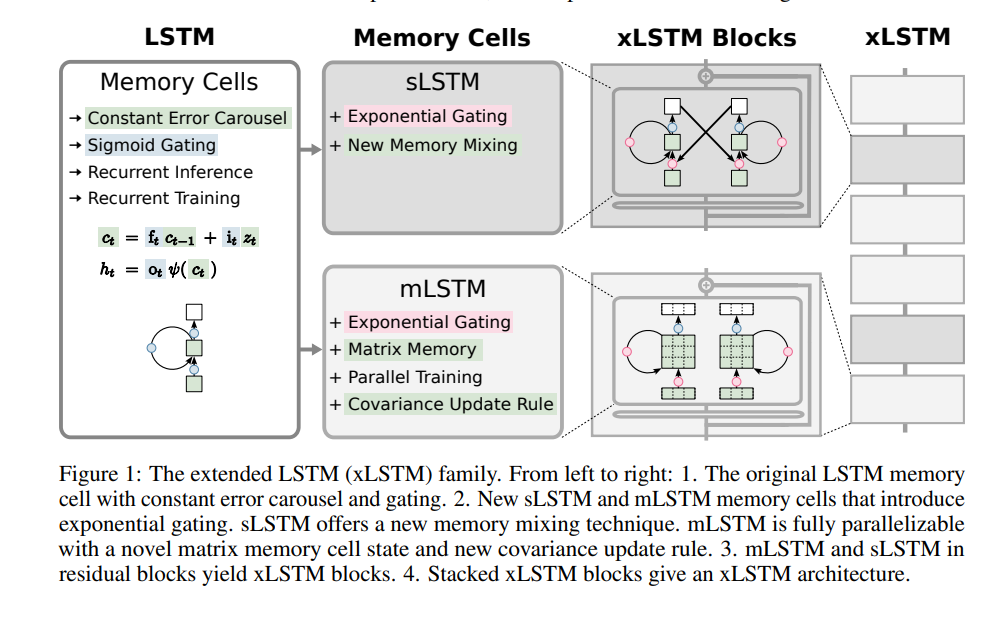
The main advantages of the xLSTM were:
Advantages of xLSTM when compared to the Transformer algorithm:
- Handling Long Sequences:
- xLSTM was specifically designed to handle long sequences with its gating mechanisms that controlled the flow of information. This made it more effective in capturing long-term dependencies in sequential data compared to the traditional LSTM.
- Computational Efficiency:
- xLSTM could be more computationally efficient for certain tasks, especially when dealing with smaller datasets or when the sequence length was not excessively large.
- Transformers, on the other hand, required significant computational resources due to their self-attention mechanism, which scaled quadratically with the sequence length.
- Memory Usage:
- xLSTM generally required less memory than Transformers.
- The self-attention mechanism in Transformers required storing large attention matrices, which could be memory-intensive, especially for long sequences.
- Training Stability:
- xLSTM could be more stable during training because of its recurrent nature and the gating mechanisms that helped in mitigating the vanishing gradient problem.
- Transformers, while powerful, could sometimes be more challenging to train and might have required careful tuning of hyperparameters and regularization techniques.
- Simplicity and Interpretability:
- xLSTM models could be simpler to understand and interpret compared to Transformers.
- The recurrent nature of LSTMs made it easier to trace the flow of information through the network, whereas the attention mechanisms in Transformers could be more abstract and harder to interpret.
- Performance on Small Datasets:
- xLSTM could perform better on small datasets or when labeled data was limited.
- Transformers typically required large amounts of data to achieve their full potential, making xLSTM a better choice in scenarios with limited data availability.
- Sequential Data:
- For certain types of sequential data, such as time series or certain types of natural language processing tasks, xLSTM might have provided better performance due to its inherent design for handling sequences.
However, it was important to note that Transformers had their own set of advantages, such as better parallelization capabilities, superior performance on large datasets, and state-of-the-art results in many NLP tasks.
The choice between xLSTM and Transformer has to be been based on the specific requirements and constraints of the task at hand.
You can see an implementation of xLSTM in PyTorch here:
https://github.com/kyegomez/xLSTM?embedable=true
You can see a detailed explanation of xLSTM here:
https://www.unite.ai/xlstm-a-comprehensive-guide-to-extended-long-short-term-memory/?embedable=true
This is a good summary of its current status:
But there was a successor to Mamba that hit the Holy Grail - the Optimal Time Complexity for a LLM algorithm.

Jamba - the Mamba Successor that beat it hands-down!
The research paper can be found here:
Jamba: A Hybrid Transformer-Mamba Language Model
https://arxiv.org/abs/2403.19887?embedable=true
From the abstract of the Research Paper:
We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture.
Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families.
MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable.
This flexible architecture allows resource- and objective-specific configurations.
In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU.
Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations.
Remarkably, the model presents strong results for up to 256K tokens context length.
We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling.
We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture.
We make the weights of our implementation of Jamba publicly available under a permissive license.
The implementation is available on the HuggingFace repository here:
Model: https://huggingface.co/ai21labs/Jamba-v0.1
- Comparison to Other Models:
- Evaluated across a range of benchmarks, Jamba demonstrates comparable performance to other state-of-the-art models such as Mistral-8x7B, Llama-2 70B, and Mixtral-8x7B.
- Notably, Jamba supports context lengths of up to 256K tokens, which is the longest among publicly available models
- In tasks like Hellaswag, Arc Challenge, and PIQA, Jamba outperforms models like Llama 2, Mixtral 8x7B, and Gemma.
In summary, Jamba’s hybrid architecture combines the strengths of Transformers and Mamba layers, resulting in impressive performance and scalability.
The key diagram to remember is the one presented in this research paper above:
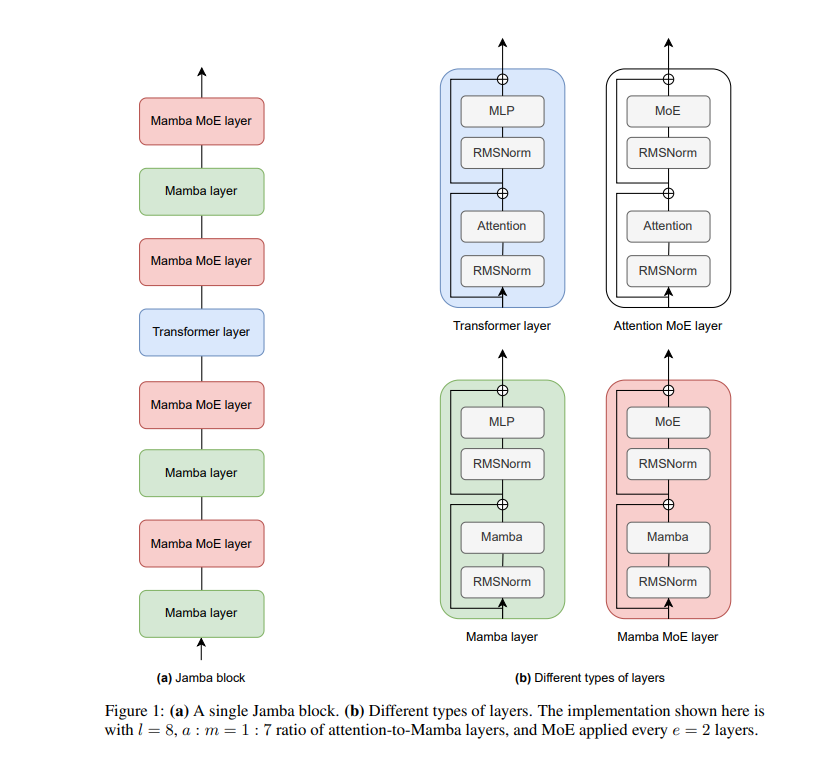
The interleaving of Mamba and Transformer models leads to an incredible increase in Time Complexity, which is beautifully summarized in the article below:
Mamba and Jamba — Simply Explained
- Author: Nimrita Koul
- Date: April 1, 2024
- Summary:
- Jamba is the first production-grade Mamba-based Large Language Model introduced by AI21.
- It combines the strengths of both Transformer and Mamba architectures.
- Transformer-based models struggle with long sequences due to their training time complexity of O(n²).
- Mamba architecture offers linear training time complexity (O(n)) and constant inference time (O(1)).
- Mamba is based on the State Space Model (SSM) architecture.
- SSMs use state variables to describe a system using differential or difference equations.
- Mamba’s hybrid approach aims to address the limitations of existing models.
You can read the full article here:
Mamba and Jamba — Simply Explained, by Nimrita Koul, on Medium.com.
The Optimal Bound Has Been Reached!
The key point to note here is that, for training, the algorithm has to look at every input token at least once, giving a time complexity of O(n).
Also, the fastest possible speed that inference can take for any LLM model is O(1) - constant time, independent of the length of the tokens (an incredible achievement)!
Both these limits have been reached in the case of the Jamba algorithm!
Therefore under constant-time improvements - which may still be very high (these numbers are in the hundreds of billions):
Jamba has reached the optimal Bound for Time Complexity for a Transformer Algorithm!
Under the given system conditions, unless new technology is introduced (quantum computing, anyone) we simply cannot have a faster asymptotic time complexity!
Which is a very significant result!

The official announcement by A121 labs:
https://www.ai21.com/blog/announcing-jamba?embedable=true
Another good article on Medium on Jamba:
One of the best implementations of Jamba available at the moment:
https://github.com/inferless/Jamba-v0.1?embedable=true
Once again, the HuggingFace Hub’s Jamba model:
https://huggingface.co/ai21labs/Jamba-v0.1?embedable=true
Conclusion
Thus Jamba reaches the ultimate time complexity that can be achieved by a current transformer algorithm under the existing system, to a constant level variation. Repeat; the constants may be very large, because these are in the order of hundreds of billions of terms! However, this is still a substantial achievement. And there are no limits to where the research on this can go especially when combined with DPO (Direct Preference Optimization) and Quantization - see the Epilogue for more.

Epilogue:
There is one side to this that no one seems to be working on openly.
Can Mamba, the xLSTM, and the Jamba models be quantized to 1-bit precision?
Of course!
I cannot wait to see Mamba’s and Jamba’s performance improvements once quantized to one-bit! Or 1.58 bit {-1, 0, 1 }.
Once again, see this article for more details:
https://hackernoon.com/why-1-bit-transformers-will-change-the-world
The future of this technology is going to be incredibly exciting!
May the joy and the thrill of working in this field always remain with you!
Cheers!

References:
Other than the ones explicitly mentioned in the article above:
- Transformer-XL: Attentive Language Models Beyond a Fixed-Length ContextDai, Z., Yang, Z., Yang, Y., Carbonell, J., & Le, Q. V. (2019). Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context.
- Longformer: The Long-Document TransformerBeltagy, I., Peters, M. E., & Cohan, A. (2020). Longformer: The Long-Document Transformer.
- Reformer: The Efficient TransformerKitaev, N., Kaiser, Ł., & Levskaya, A. (2020). Reformer: The Efficient Transformer.
- Linformer: Self-Attention with Linear ComplexityWang, S., Li, B. Z., Khabsa, M., Fang, H., & Ma, H. (2020). Linformer: Self-Attention with Linear Complexity.
- State Space Models: A General Framework for Modeling Time Series DataDurbin, J., & Koopman, S. J. (2012). State Space Models: A General Framework for Modeling Time Series Data.
- S4: Sequence Modeling with Structured State SpacesGu, A., Goel, K., & Re, C. (2021). S4: Sequence Modeling with Structured State Spaces.
- On the Computational Efficiency of Large Language ModelsAnonymous authors. (Year not specified). [On the Computational Efficiency of Large Language Models](URL not provided).
- Efficient Transformers: A SurveyTay, Y., Dehghani, M., Bahri, D., & Metzler, D. (2020). Efficient Transformers: A Survey.
- Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only InferenceJacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., ... & Adam, H. (2018). Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference.
- Q-BERT: Hessian Based Ultra Low Precision Quantization of BERTShen, S., Dong, Z., Ye, J., Ma, L., & Gholami, A. (2020). Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT
- BERT: Pre-training of Deep Bidirectional Transformers for Language UnderstandingDevlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
- GPT-3: Language Models are Few-Shot LearnersBrown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., ... & Amodei, D. (2020). GPT-3: Language Models are Few-Shot Learners.
- RoBERTa: A Robustly Optimized BERT Pretraining ApproachLiu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. (2019). RoBERTa: A Robustly Optimized BERT Pretraining Approach.
- ALBERT: A Lite BERT for Self-supervised Learning of Language RepresentationsLan, Z., Chen, M., Goodman, S., Gimpel, K., Sharma, P., & Soricut, R. (2019). ALBERT: A Lite BERT for Self-supervised Learning of Language Representations.
- T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text TransformerRaffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2019). T5: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
- DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighterSanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.

For the Prologue and Epilogue
For quantization, this paper is definitely worth a read:
- Research Paper - BitNet: Scaling 1-bit Transformers for Large Language Models:
- From the Abstract*: Experimental results on language modeling show that* BitNet achieves competitive performance while substantially reducing memory footprint and energy consumption compared to state-of-the-art 8-bit quantization methods and FP16 Transformer baselines. Furthermore, BitNet exhibits a scaling law akin to full-precision Transformers*, suggesting its potential for effective scaling to even larger language models while maintaining efficiency and performance benefits.*
- Read the full research paper
- https://arxiv.org/abs/2310.11453
And the model on HuggingFace:
- Hugging Face Repository - BitNet b1.58-3B Quantized:
- This repository contains a quantized version of the BitNet b1.58-3B model
- Explore the Hugging Face model
- https://huggingface.co/kousw/bitnet_b1_58-3B_quantized
