

Authors:
(1) Kedan Li, University of Illinois at Urbana-Champaign;
(2) Min Jin Chong, University of Illinois at Urbana-Champaign;
(3) Jingen Liu, JD AI Research;
(4) David Forsyth, University of Illinois at Urbana-Champaign.
Table of Links
3. Proposed Method
Our method has two components. A Shape Matching Net (SMN; Figure 2 and 3) learns an embedding for choosing shape-wise compatible garment-model pairs to perform transfer. Product and model images are matched by finding product (resp. model) images that are nearby in the embedding space. A Multi-warp Try-on Net (MTN; Figure 4) takes in a garment image, a model image and a mask covering the to-change garment on the model and generates a realistic synthesis image of the model wearing the provided garment. The network consists of a warper and an inpainting network, trained jointly. The warper produces k warps of the product image, each specialized on certain features. The inpainting network learns to combine warps by choosing which features to look for from each warp. SMN and MTN are trained separately.

3.1 Shape Matching Net
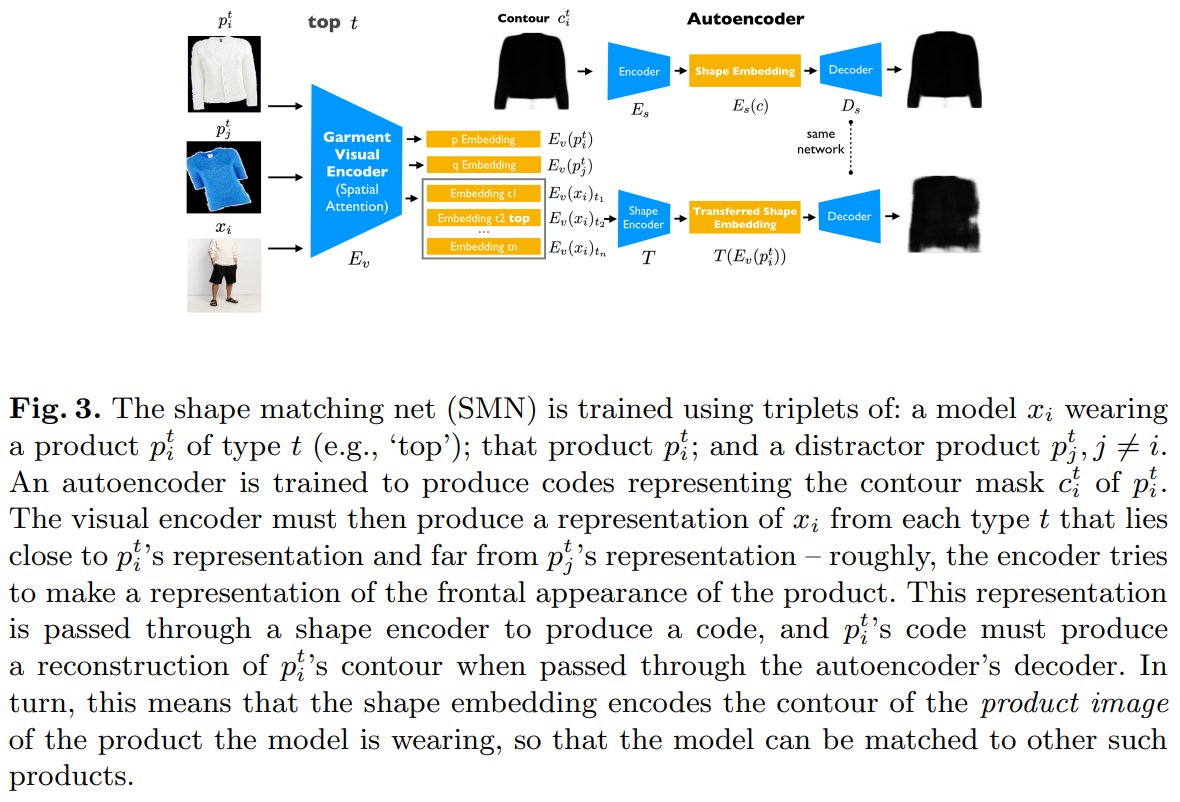

The embedding loss is used to capture the feature correspondence of the two domain and help enforce the attention mechanism embed in the network architecture. Details about the spatial attention architecture are in Supplementary Materials.

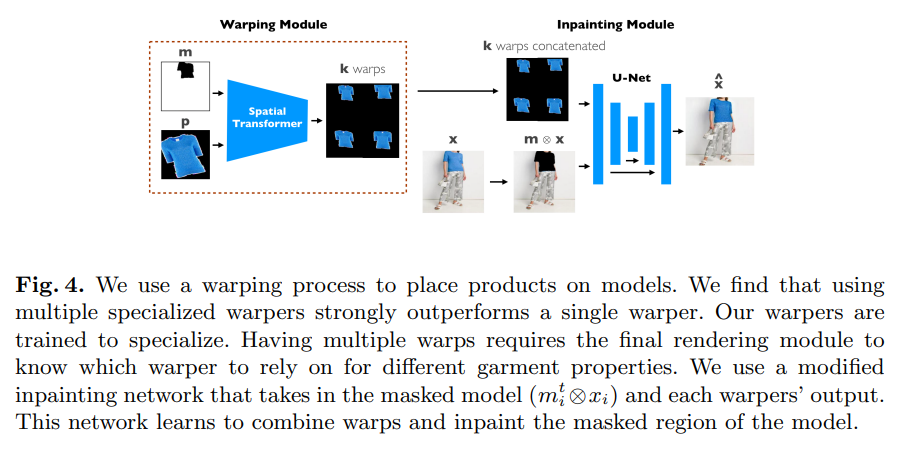
3.2 Multi-warp Try-on Net
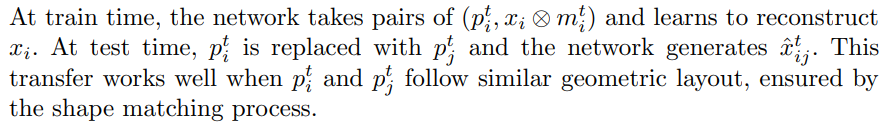
As with prior work [17,45], our system also consists of two modules: (a) a warper to create multiple specialized warps, by aligning the product image with the mask; (b) an inpainting module to combine the warps with the masked model and produce the synthesis image. Unlike prior work [17,45], the two modules are trained jointly rather than separately, so the inpainter guides the warper.


Cascade Loss: With multiple warps, each warp wi is trained to address the mistakes made by previous warps wj where j < i. For the k th warp, we compute the minimum loss among all the previous warps at every pixel, written as

The cascade loss computes the average loss for all warps. An additional regularization terms is enforced on the transformation parameters, so all the later warps stay close to the first warp.
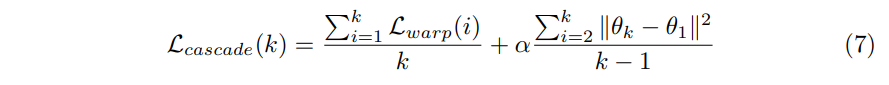
The cascade loss enforce a hierarchy among all warps, making it more costly for an earlier warp to make a mistake than for a later warp. This prevents possible oscillation during the training (multiple warps compete for optimal). The idea is comparable with boosting, but yet different because all the warps share gradient, making it possible for earlier warps to adjust according to later warps.

This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.