Authors:
(1) PIOTR MIROWSKI and KORY W. MATHEWSON, DeepMind, United Kingdom and Both authors contributed equally to this research;
(2) JAYLEN PITTMAN, Stanford University, USA and Work done while at DeepMind;
(3) RICHARD EVANS, DeepMind, United Kingdom.
Table of Links
Storytelling, The Shape of Stories, and Log Lines
The Use of Large Language Models for Creative Text Generation
Evaluating Text Generated by Large Language Models
Conclusions, Acknowledgements, and References
A. RELATED WORK ON AUTOMATED STORY GENERATION AND CONTROLLABLE STORY GENERATION
B. ADDITIONAL DISCUSSION FROM PLAYS BY BOTS CREATIVE TEAM
C. DETAILS OF QUANTITATIVE OBSERVATIONS
E. FULL PROMPT PREFIXES FOR DRAMATRON
F. RAW OUTPUT GENERATED BY DRAMATRON
3 THE USE OF LARGE LANGUAGE MODELS FOR CREATIVE TEXT GENERATION
3.1 Language Models
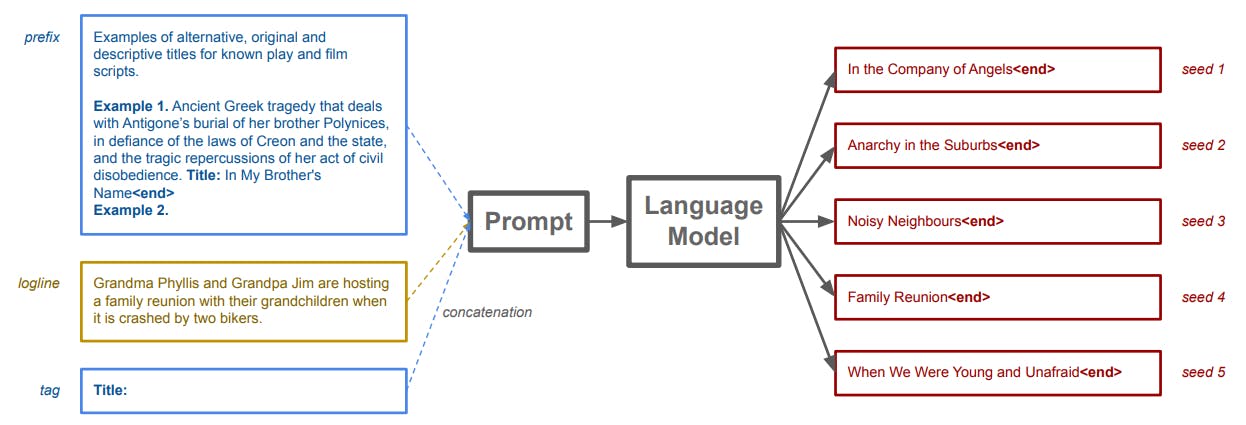
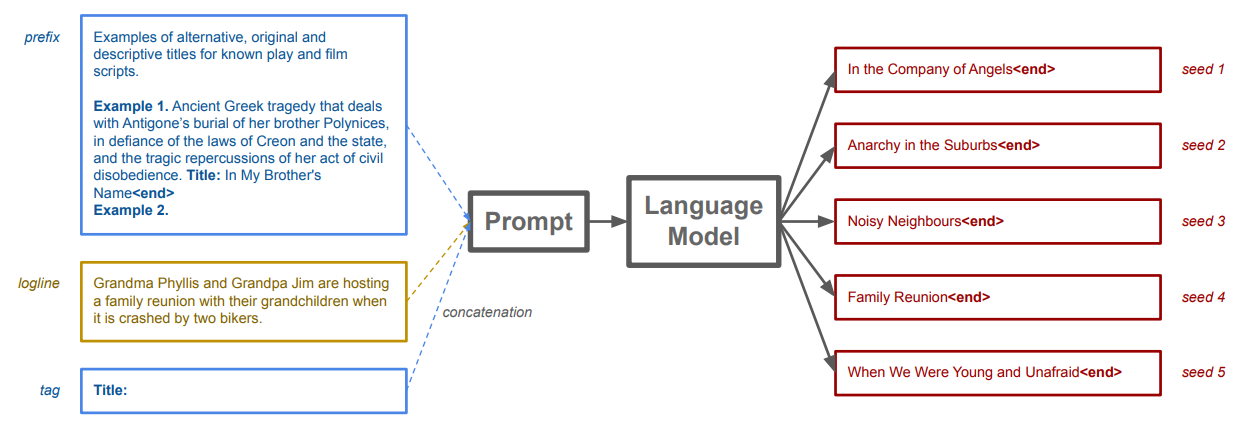
Statistical language models (language models, or LMs) model the probability of text tokens given a context of previous tokens—tokens can be words, characters, or character bi-grams. Using machine learning, LMs are trained on large corpora of text to approximate the conditional probability distribution. LMs can compute the likelihood of a piece of text and generate new text as the continuation of a text prompt. Text generation is probabilistic and involves random sampling from the conditional probabilities. Different random seeds result in different random samples. Figure 3 illustrates an example of feeding a text prompt and using the LM to generate different text samples.
In this study, we employed the Chinchilla large language model (LLM) [48], represented as a neural network with 70B-parameters and that was trained on 1.4T tokens of the MassiveText dataset. As described by Rae et al. [84], that corpora contains 604M MassiveWeb documents, 4M Books, 361M questions and responses from C4, 1.1B News articles, 142M GitHub code entries, and 6M Wikipedia articles. Note that alternative LLMs could be employed, such as GPT-3.[1]
3.2 Hierarchical Language Generation to Circumvent Limited Contexts

In this project, we desire a system that can generate an entire text exhibiting long-term semantic coherence without necessarily requiring a human-in-the-loop. We encourage writers to edit and modify the script at every level of the hierarchy. But, we do not require a human-in-the-loop to achieve long-term semantic coherence. The hierarchical method will generate an entire script exhibiting reasonable long-term coherence from a single log line without human intervention. Our approach to achieve long-term semantic coherence is to generate the story hierarchically.
Our narrative generation is divided into 3 hierarchical layers of abstraction. The highest layer is the log line defined in Section 2: a single sentence describing the central dramatic conflict. The middle layer contains character descriptions, a plot outline (a sequence of high-level scene descriptions together with corresponding locations), and location descriptions. The bottom layer is the actual character dialogue for the text of the script. In this way, content at each layer is coherent with content in other layers. Note that “coherent” here refers to “forming a unified whole”, not assuming any common sense and logical or emotion consistency to the LLM-generated text.
As illustrated on Figure 1, the story is generated top-down [93, 108, 113]. After the human provides the log line, Dramatron generates a list of characters, then a plot, and then descriptions of each location mentioned in the plot. Characters, plot, and location descriptions all meet the specification in the log line, in addition to causal dependencies, enabled by prompt chaining [118] and explained on the diagram of Figure 1. Finally, for each scene in the plot outline, Dramatron generates dialogue satisfying previously generated scene specifications. Resulting dialogues are appended together to generate the final output. This hierarchical generation was designed to enable long-term semantic coherence. A similar albeit inverted, method of recursive task decomposition was used to generate plot summaries [117]. The incorporation of the middle layer, where the plot is summarised as a sequence of abstract scene descriptions, allows the entire plot to fit within the language models’ context window. This overcomes prior limitations on long-term semantic coherence. Our method makes it possible for elements in the final scene to provide dramatic closure on elements introduced in the opening scene[3], and for generated stories to follow narrative arcs (see Section 2).
3.3 The Importance of Prompt Engineering
Dramatron uses several hard-coded prompts (i.e. input prefixes) to guide the large language model. Prompt engineering is a common way that users control or influence LLMs [12]. Each prompt has a few examples of desirable outputs. These are included in the prefix and adaptation to only a handful of examples is sometimes referred to as few-shot learning. As illustrated in Figure 3, prompts are concatenated with user-supplied inputs and/or outputs of previous LLM generations. This method is called prompt chaining [118], which is a type of algorithmic prompting [24]. At lower levels of the hierarchy (see Fig. 1), prompts are chained together with outputs from higher levels of the hierarchy.
In this work, we primarily used two sets of prompts: one based on Ancient Greek tragedy Medea by Euripides, and one based on science-fiction films. For Dramatron, each prompt set is composed of: 1) title prompt, 2) character description prompt, 3) plot prompt, 4) location description prompt, 5) and dialogue prompt. Each prompt is detailed briefly below to give a sense of how they are engineered; additional details are in Appendix E.
The Title Prompt is used to generate titles from a log line. A simplified title prompt, a user-provided log line, and randomly sampled titles are shown in Figure 3. It shows a prefix with an instruction (Examples of alternative, original and descriptive titles for known play and film scripts.) and an example (Example 1. Ancient Greek tragedy [...]. Title: In My Brother’s Name). The prefix finishes with: Example 2. A user-input log line (e.g., Grandma Phyllis and Grandpa Jim [...]) is concatenated to that prefix, as well as the tag Title:, which encourages the LLM to generate a title that matches the log line. From a few examples, the LLM has “learned” to generate a related title and terminate tag . The Character Description Prompt is used to generate character names and descriptions from a log line. The Plot Outline Prompt is used to turn a log line and list of characters into a plot. This prompt encourages the few-shot language model to transform a single sentence log line into a sequence of scene descriptions. Each scene is highly compressed, describing only the short name of the location, the narrative element identifying the position of the scene in the narrative arc (see Sec. 2), and a summary of what the characters are doing and saying, often called a narrative beat[69]. As a note, the prompt imposes a strong representational constraint on the way Dramatron represents a scene; each scene is composed of a location, narrative element identifier, and beat. The Location Description Prompt is used to generate a detailed scenic description from a place name and a log line. Finally, the Dialogue Prompt is used to turn a beat (i.e., the scene summary), scene location description, description of each of the characters involved in the scene, and the log line (for story consistency), into dialogue. This prompt uses scene information generated for both the current and previous scenes.
3.4 Interactive Writing with Dramatron
As described above, with just few-shot (i.e., 1-4) prompts and the user input log line, we leverage trained LLMs to generate complete scripts and screenplays. Appendix F shows an example of raw generated output. That said, Dramatron is designed for interactive co-writing, as an augmentative tool for human writers. Co-authorship with Dramatron proceeds as follows: A writer starts with a log line that they have written. They input that log line into Dramatron, and generate a title, characters, a plot outline, location descriptions and each scene’s dialogue step-by-step. At each step, the writer can take one, or several, of the following operations, as many times as desired:
• Generate a new suggestion (i.e., run the LLM again with the same prompt).
• Continue generating from the end of the previous generation, similarly to typical “flat” LLM generation.
• Manually edit some or all of the output generated by the LLM.
The writer can furthermore perform these operations by stepping forward and back in the Dramatron hierarchy. For example, they could: 1) generate a title, 2) generate a new title, 3) edit the title, 4) generate a list of characters, 5) edit the characters by removing one character and changing the description of another, 6) generate a plot outline, 7) edit the plot by removing part of the narrative arc, 8) generate a continuation of that edited plot, 9) go back and rewrite the log line, etc. This co-writing approach allows the human and Dramatron to both contribute to the authorship of a script. Following these operations, the human author could further edit and format to finalize a script. Appendix G shows examples of human-edited scripts.
3.5 Implementation Details
The code of Dramatron is implemented in Python and the user-facing interface was implemented in a Google Colab[4] with text widgets, allowing interactive editing. There are several special markers we use for script generation: represents the end of full sequence generation token, and is a token used to mark the end of a generated line. For a given prompt (see next Sec. 3.3) fed to the LLM, up to 511 text tokens were sampled. We used Nucleus sampling [49] to encourage diverse outputs, sampling tokens from the top 0.9 probability mass, and with a softmax temperature of 1.0. Finally, in order to reduce loops in the generation of dialogue, we implemented a simple detector that cuts the generated text into blocks (delimited by 2 blank lines) and counts how many times each block appears in one single generation. Beyond a fixed threshold (e.g., 3 times), the LLM generates a new output by sampling tokens using a different seed in the random number generator.
This paper is available on arxiv under CC 4.0 license.
[1] Accessible at: https://openai.com/api/
[2] For example: https://theguardian.com/commentisfree/2020/sep/08/robot-wrote-this-article-gpt-3
[3] See e.g. Chekhov’s gun [27].
[4] https://colab.research.google.com/