In this article, we will discuss the complexities of monitoring distributed databases from the perspective of a monitoring system developer. I will try to cover the following topics: managing multiple nodes, network restrictions, and issues related to high throughput caused by a large number of metrics. We will consider the trade-offs and address the following challenges:
- Built-in vs dedicated exporters.
- The limitations of industry standards like Open Telemetry in specific cases.
- The cost of fetching schema and data of metrics.
- Consistency in global state synchronization.
- Complexity in supporting connections in a cloud.
The topics mentioned above are based on my experience with the development of a cloud monitoring solution for the distributed database Apache Ignite. I want to share valuable insights that may be useful for developers who wish to create their monitoring systems.
Introduction
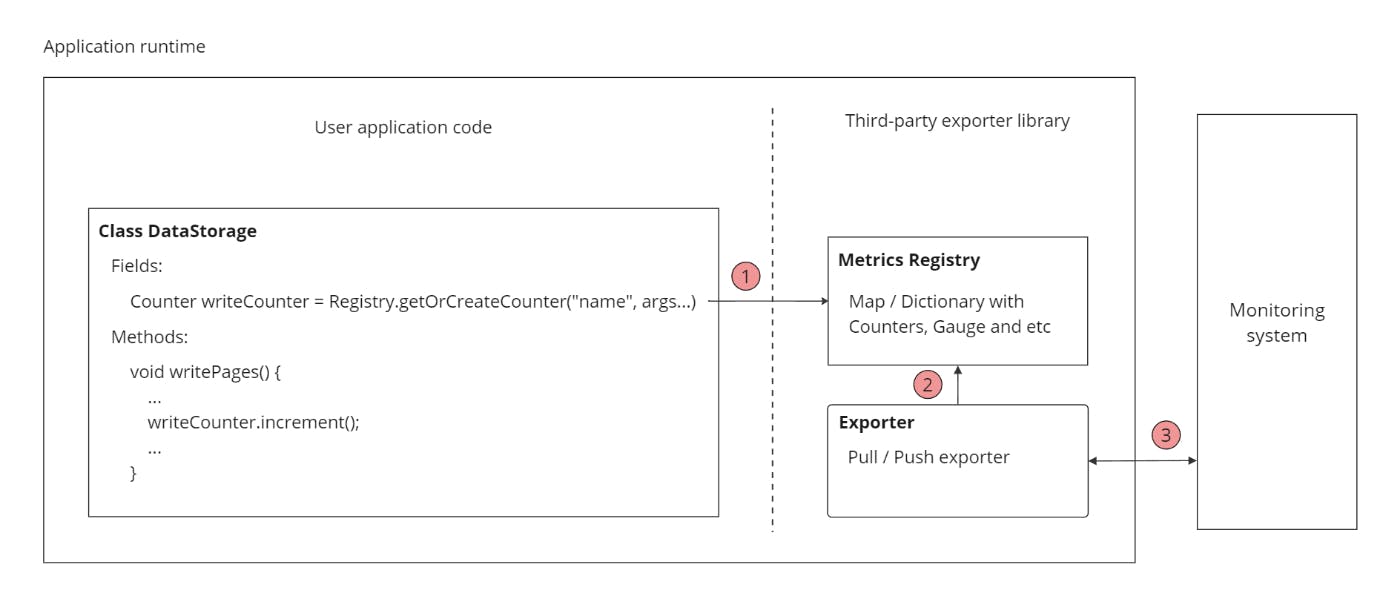
The reason for this challenge is that there is no universal optimal solution, as there are tradeoffs and limitations in each system that make it difficult to find a perfect implementation. Our discussion begins with a basic example of an abstract metric collection system. As illustrated in this example, there are several points where we may have varying discussions based on specific requirements.
For instance, at point one, we can choose between different implementations of the metrics registry, which can store them in memory or persist them on disk. The Metric registry is an intermediate structure that stores measurements before exporting. It is important to understand that there are various reasons why we might have different approaches to our custom monitoring system:
- Footprint - is the amount of memory consumed. IoT applications, where memory is limited, need a solution that uses less.
- Memory pressure - is a result of object allocation that may affect your application for languages with auto garbage collection.
Most default implementations don't care about this, they use a regular in-memory data structure. At point two, we can discuss what we want to do when we experience backpressure or connection loss. At point three, we can evaluate the most suitable protocol and data acquisition approach. Despite the fact that we don't cover any trade-offs of metric collection in distributed systems, we can see how controversial the simple implementation of this approach can be.
System requirements
When designing a system, the first step is usually to estimate the hypothetical load, such as the input size, scaling plans, number of users, and business constraints.
We will extract metrics from the distributed database that has N nodes in the general case. These metrics will provide information about objects and their associated processes.
In my scenario, I have considered metrics of two different types:
- Statically defined metrics - are metrics like CPU, Memory, Avg Transaction time, etc (Their count is about 100).
- Dynamically defined metrics - are metrics that are created on each entry like cache, table, queue, data region, indexes and etc (The average size per entry is about 30).
Dear reader, as you might have noticed the problem here is dynamic creating metrics because their amount depends on the particular environment. But anyway, let's try to estimate its amount:
- The number of tables, caches, and indexes in a medium-sized application is approximately 250.
- As a result, we have 100 + 30 * 250 = 7600 metrics per node.
- An average cluster has around 10 nodes.
- The number of global cluster metrics is 7600 * 10 = 76_000;
- If we look at the Gauge metric. It has the following fields: Name, Description, Unit, and Data. When the number of metrics is 76_000, the size of the payload is around 256 bytes * 76_000 => 19Mb per request.
As demonstrated, sending all metrics without any filtering may not be the best approach, as it could lead to wasted space and unnecessary network traffic. Additionally, it may be unrealistic for a user to monitor 7600 different metrics, which are obtained through aggregation by nodes.
One of the advantages of the metric collecting system is its ability to scale effectively. This allows us to allocate separate instances for storing data for each cluster, ensuring that the data is independent and partitioned effectively. Let’s imagine that we have a microservice that can serve 50 clusters per instance. Despite the fact that a cluster has thousands of metrics, typical users use much fewer.
They have 12 dashboards + 12 alerts with around 4 metrics per dash/alert. Hence when the metric collecting interval is 5 - 10 sec:
-
50 clusters * (12 dash + 12 alert) * 4 metrics * (31 * 24 * 60 * 60 / 5) intervals in month = 2571264000 metrics stored per month
-
2571264000 * (64 + 32) metric size in bits (in the ignite persistent cache) = 230 GB
To address the issue of excessive storage space, we will compress the metrics and only store the timestamp (as an int64) and the value (as an int32) as repeatable data. This type of data is friendly with compression algorithms. If a time series database is used, timestamps for the same time will not be repeated.
Therefore, as we can see, we need to provide 230 GB of storage each month If we don't have an expiration policy for our data. In our case free users usually have 7 days and paid users have more that covers our costs.
In addition, another assumption worth considering is the read/write ratio. This is useful because it helps us choose the right database for our data. However, in our case, we do not have a choice, so we store it in Apache Ignite.
The solution is step by step
Data Acquisition Method
🙋Question to the audience: Which type of collection model do you prefer? (Options: push / poll / both / I don't have a particular opinion.)
In essence, when dealing with an abstract pipe, there are two main ways to move something from it - either by pushing something into the pipe or by pulling it out. In our specific case, where the pipe represents a network, we are considering two types of data acquisition methods.
Push (CollectD, Zabbix, and InfluxDB)
With the push approach, each application instance pushes data at a set time interval. This means that the data is actively pushed from the application to the database or storage system, based on a predefined schedule or frequency.

Advantages:
- Don’t require a service complex discovery.
Disadvantages:
- It requires configuration on each independent agent node.
I have mentioned the pons and cons of supporting the N node of the database. You may notice that each node needs to be configured separately, which can be time-consuming and prone to errors. While automation tools like Ansible can be used to streamline the configuration process, it still requires some level of manual effort. Additionally, updating configurations can be challenging as it requires modifying each individual node.
Pull (Prometheus, SNMP, and JMX)
The pull method of acquiring metrics involves the external monitoring system that requests the collection of metrics as needed.

Advantages:
- Centralized configuration can be easily managed within the monitoring system.
- Backpressure is handled automatically.
- You can request only the required metrics.
Disadvantages:
- Require service discovery.
- Require monitoring needs to have the capability to be accessed remotely.
In our case, the pull method offers more benefits than the push method, but it also has some significant drawbacks, which we explored when we began working in an enterprise environment. One of these drawbacks is a network firewall, which blocks all incoming connections from the public network to the private network. To solve this problem, we implemented a hybrid approach.
The Ignite 2 acquisition model
For Ignite 2, we initially used the traditional pull method for metric collection, as it seemed like the most straightforward approach. However, we had to incorporate data filtering, because the unfiltered average response size was 19 MB every 5 seconds. This became too much for us to handle as we added more clusters.
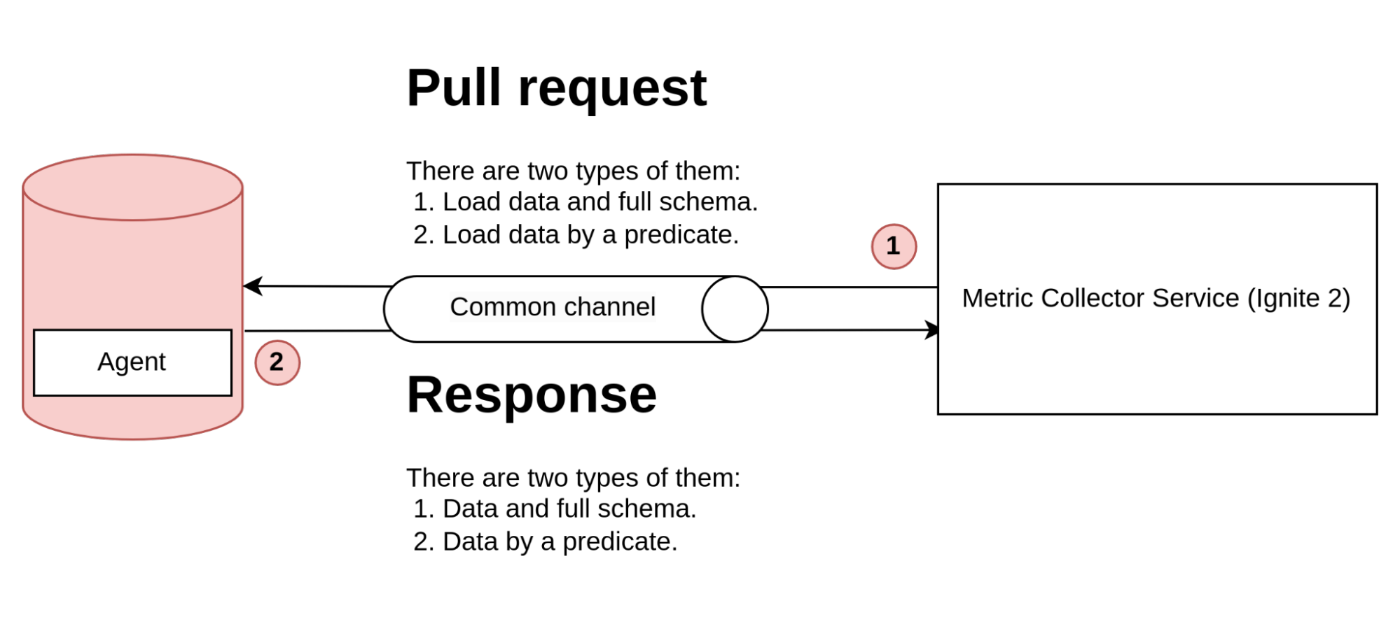
To collect metrics, our process involves two asynchronous steps. Firstly, we send a pull request with no arguments, which begins collecting all available metrics. In the second step, the collector receives these metrics and the process repeats. In subsequent iterations, we apply a filter to reduce the amount of data collected in subsequent requests. However, the first request must be empty for collecting full metrics schema.
When the schema is outdated, the agent sends a new version. The agent is an embedded plugin that handles the database connection and serves metrics requests.
What is wrong here:
- Most pulls have the same payload, which leads to wasted traffic when the same message is sent multiple times.
- The data and schema requests are sent together, which makes the data model complex and makes it difficult to retrieve the data separately from the schema.
These issues can cause performance and efficiency problems in the metric collection process.
If you're wondering why the protocol has not been changed, it's because the current system supports multiple versions of agents. If the protocol was changed, the collector would have to support both old and new versions, which would add complexity to the system.
The Ignite 3
In the second version of our integration with Ignite 3, we made some changes to the protocol by splitting messages into different types: Schema Update Messages and Metric Polling Messages that can set a filter for future requests.
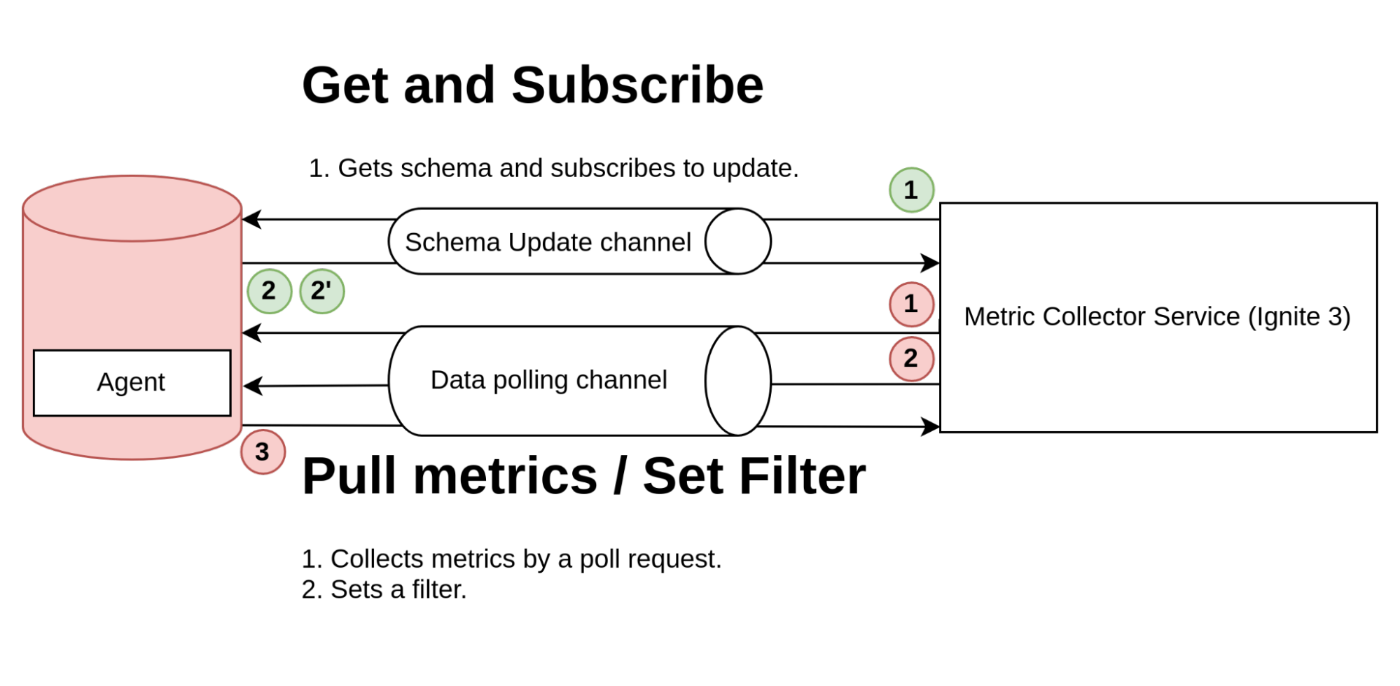
The schema collecting involves the following steps (green circles):
- The application initiates the process (1) by requesting the schema of metrics and subscribing to updates.
- The collector sends a response (2) containing the full schema of metrics. When there are updates to the schema, it sends an update (2') to the application.
Metric collecting involves the following steps (red circles):
- In the metric collecting process, the collector sends a filter setting in the first request (1) to specify the type of metrics to collect in future requests.
- Then, in subsequent requests, the collector sends metric requests (2) and receives responses (3) containing the requested metrics.
This approach significantly reduces traffic consumption and is now our target protocol.
Network Structure
The choice of acquisition model can impact the area of monitoring usage. It's important to consider the limitations of the network layers when designing a monitoring system.
Public networks
In a public network scenario where each part of the system is accessible to the public, there are generally no issues with using either the push or pull acquisition model. Since all components are publicly available, the monitoring system can easily request data from the application instances using the pull method or receive data pushed by the instances using the push method.
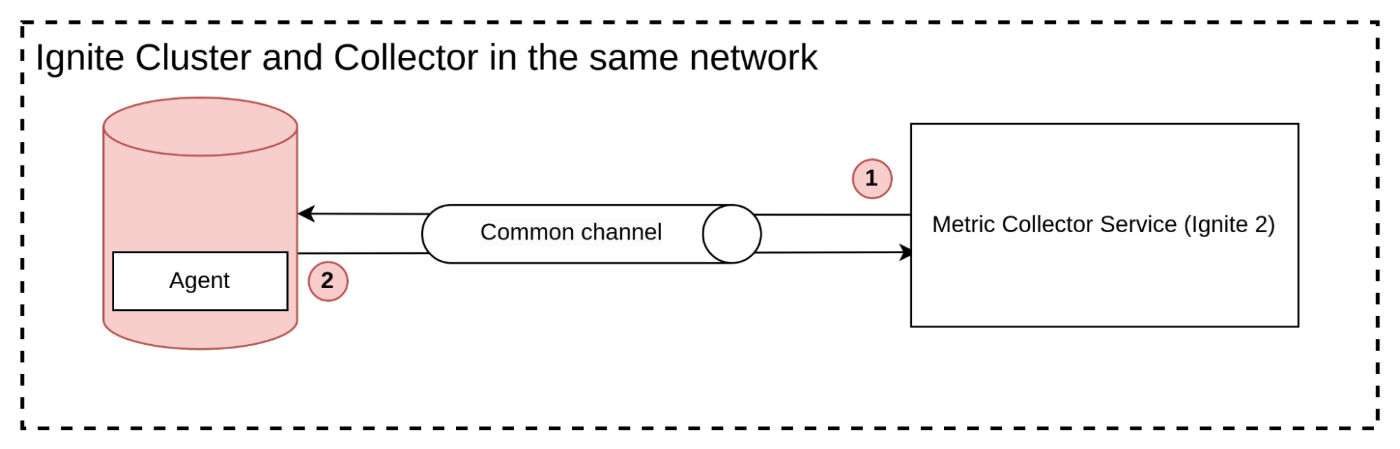
Unfortunately, this approach is not possible in enterprise development, as it has security concerns, such as open ports being a potential attack vector in certain scenarios.
Private networks
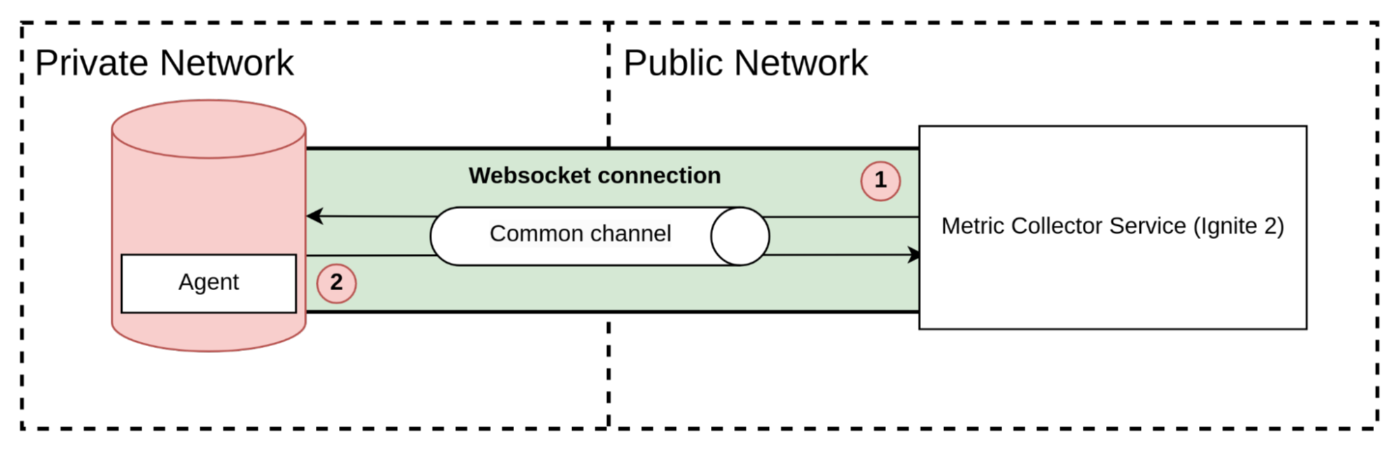
In private networks where database clusters are usually located, security concerns require that the network is not directly accessible from outside. As a result, the collector cannot pull metrics directly from the cluster, making the push acquisition method the more suitable option for this scenario.

The push model offers an advantage in this case, as the agent can establish an outgoing connection to the public address of the collector. If we want to use the pull method in a private network scenario, we need to establish a connection between the two networks. This can be done through various means, such as a VPN (Virtual Private Network), AWS PrivateLink, an agent proxy, or other similar solutions. These bridges allow the collector to pull the metrics from the private network by establishing a connection through the bridge. However, this approach requires additional setup and maintenance of the bridge infrastructure.
The ignite 2/3 networks
To support a connection between private and public networks was decided against using VPN or other complicated approaches as they may be difficult for customers and cause them to leave. Instead, it opens a TCP connection (using WebSocket, as most ports in the bank are disabled) from the agent to the collector, which the collector uses for pulling metrics.
Agent / Exporters
The agent/exporter is part of a metric collection system, that collect metrics from metric source and supply them to a store. There are several ways where an exporter can be located: An application can include an agent in the classpath hance the agent is started with the application together. The agent can be located outside of the application on the same instance or in the same network. The application is able to support an open protocol with direct calls like JMX and REST but this case is similar to the agent inside.
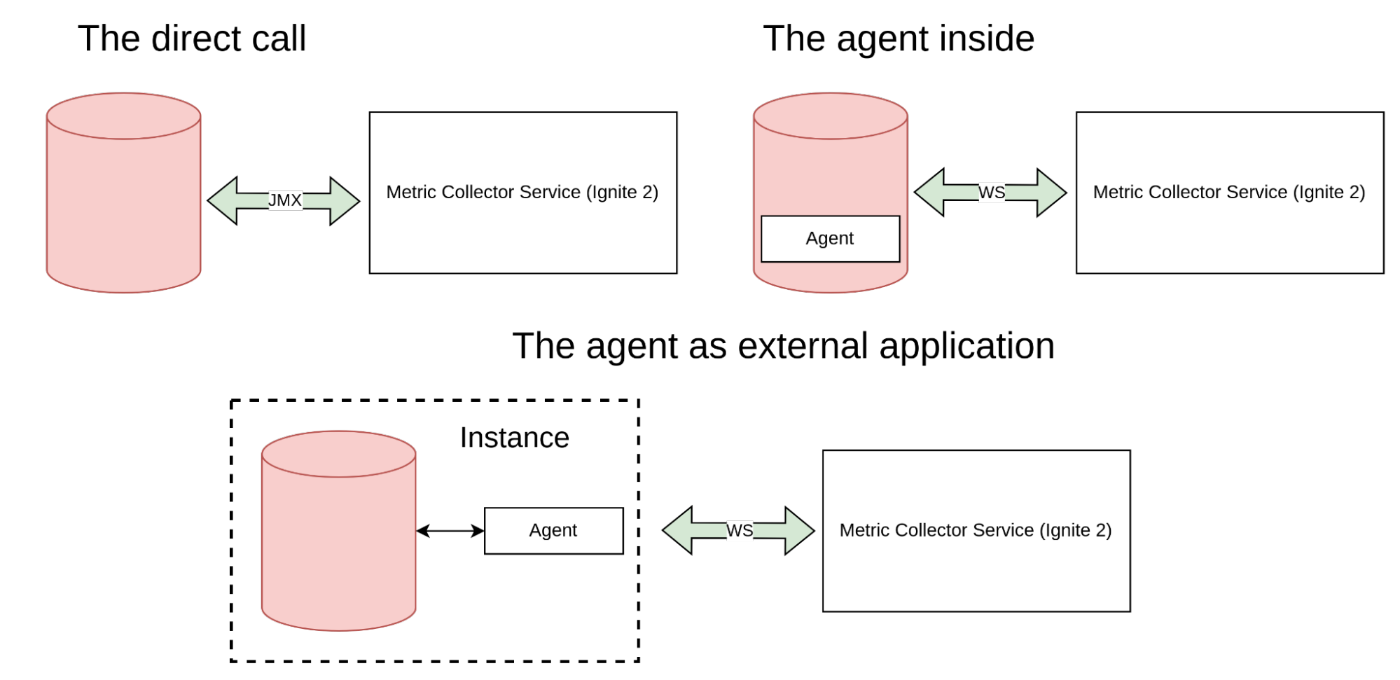
The agent inside of an application
The agent that operates within an application can be compared to an included library in the application's runtime, such as the Prometheus agent. One advantage of this approach is the ease of adding metric exports to systems that lack metrics by relying on common frameworks that can be easily patched to provide application metrics. Another benefit is when implementing an abstract metric framework, where the agent serves as an implementation of an exporter for a specific collection system.
However, there are also drawbacks to this approach. The main disadvantage is that external code is executed in the same runtime as the application, in this case, the database, which can lead to side effects:
- These side effects include crashes due to out-of-memory errors because the exporter inside uses buffers.
- There may also be crashes due to bugs, especially if the code uses unsafe code, leading to issues in environments with different byte orders.
- There is an extra footprint and garbage collection pauses.
- Rolling upgrade issues, where the instance of the database must be stopped to update the dependency
- Finally, there are potential security issues to consider as well.
The agent outside of an application
The agent outside of an application is a different approach where an external agent application is installed in the same instance as the business application. This eliminates the direct dependency on the collecting system and the disadvantages of the agent inside approach.
However, this approach comes with a cost of support as two applications need to be managed instead of one. The performance may be slightly lower, but it's not a critical issue. This method would be preferred if not for one problem, which will be discussed below.
The ignite agent and our discussion
We developed a plugin for Ignite 2 that establishes a connection with our cloud and sends metrics. We are also exploring the possibility of using the same approach for Ignite 3 integration. Initially, we considered using an external exporter because it is safer for the customer cluster, but we also had to consider the business value of reducing the manual installation steps.
We thought about supporting two types of agents - inside and outside - and recommending the migration to the outside version in cases with better performance and stability. However, this approach would require twice the support efforts.
Therefore, we decided to stick with the inside version of the agent. Although this approach has advantages, especially in a distributed system, we will explore this further below. In brief, we can leverage our access to internal database services responsible for consensus, and reuse them for our purpose.
Scalability (Global or Local metrics)
The following section will examine the challenges of monitoring in a distributed environment, as opposed to monitoring a single application. We will explore how the Push/Pull acquisition methods apply in the context of microservice architecture or distributed databases.
Push on each node
In my opinion, the Push on each node model is ideal for resolving many issues in distributed systems. This approach involves each node having a direct connection between an agent and a collector, which is beneficial for handling split-brain scenarios. If a section of the cluster separates, it will stop sending metrics automatically.
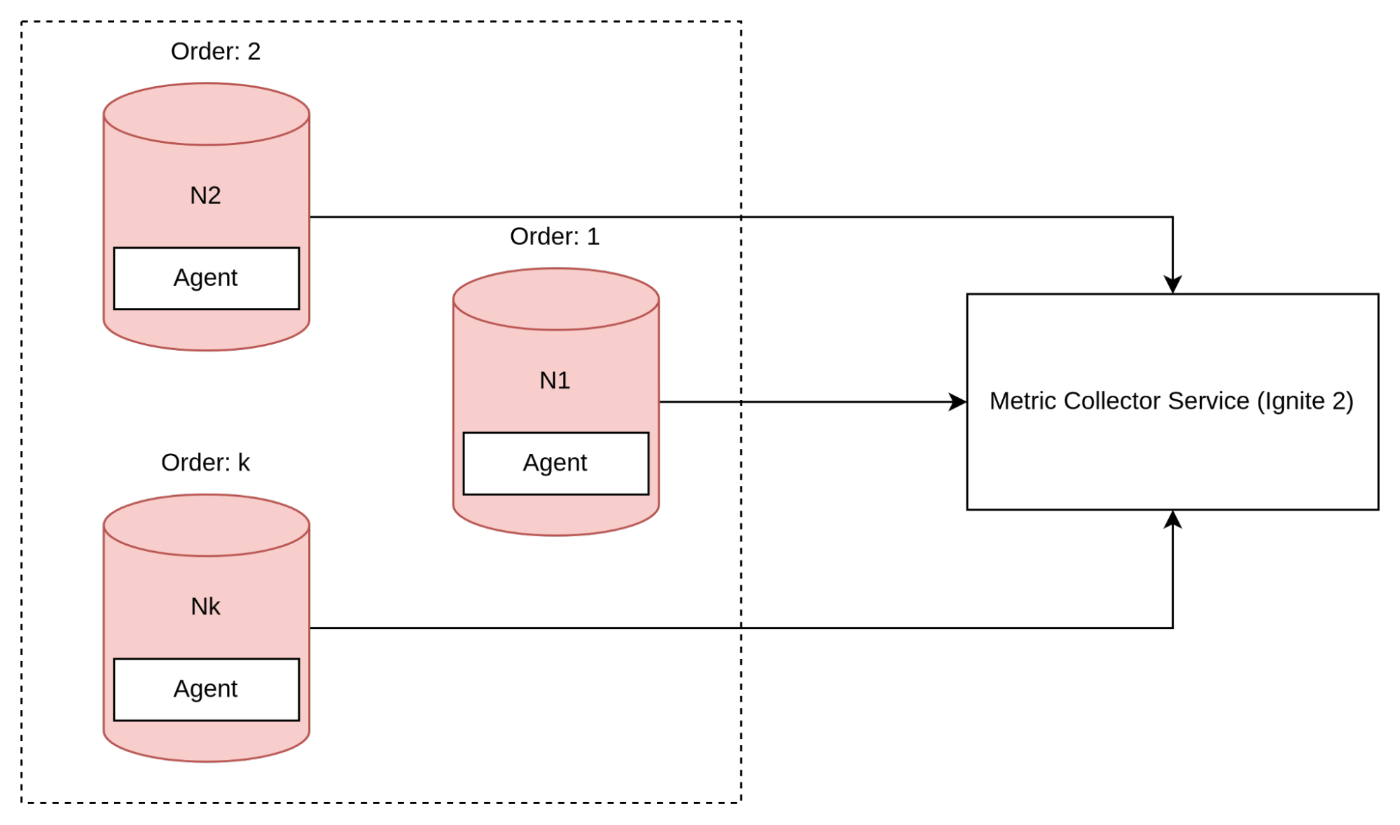
Advantages:
- Automatic scaling without the need for service discovery.
- Reduced traffic for resending data.
- Elimination of a single point of failure.
Disadvantages:
- The socket connection may pose a problem, although it can be mitigated by using virtual addresses and opening more than 65k connections.
- Time synchronization can be challenging when merging data.
Pull on each node
In a traditional architecture, using the Pull acquisition method on each node in a distributed system requires a more complex interaction schema. To accommodate for nodes being launched and losing connection with other instances, each node must register itself in a service discovery component.
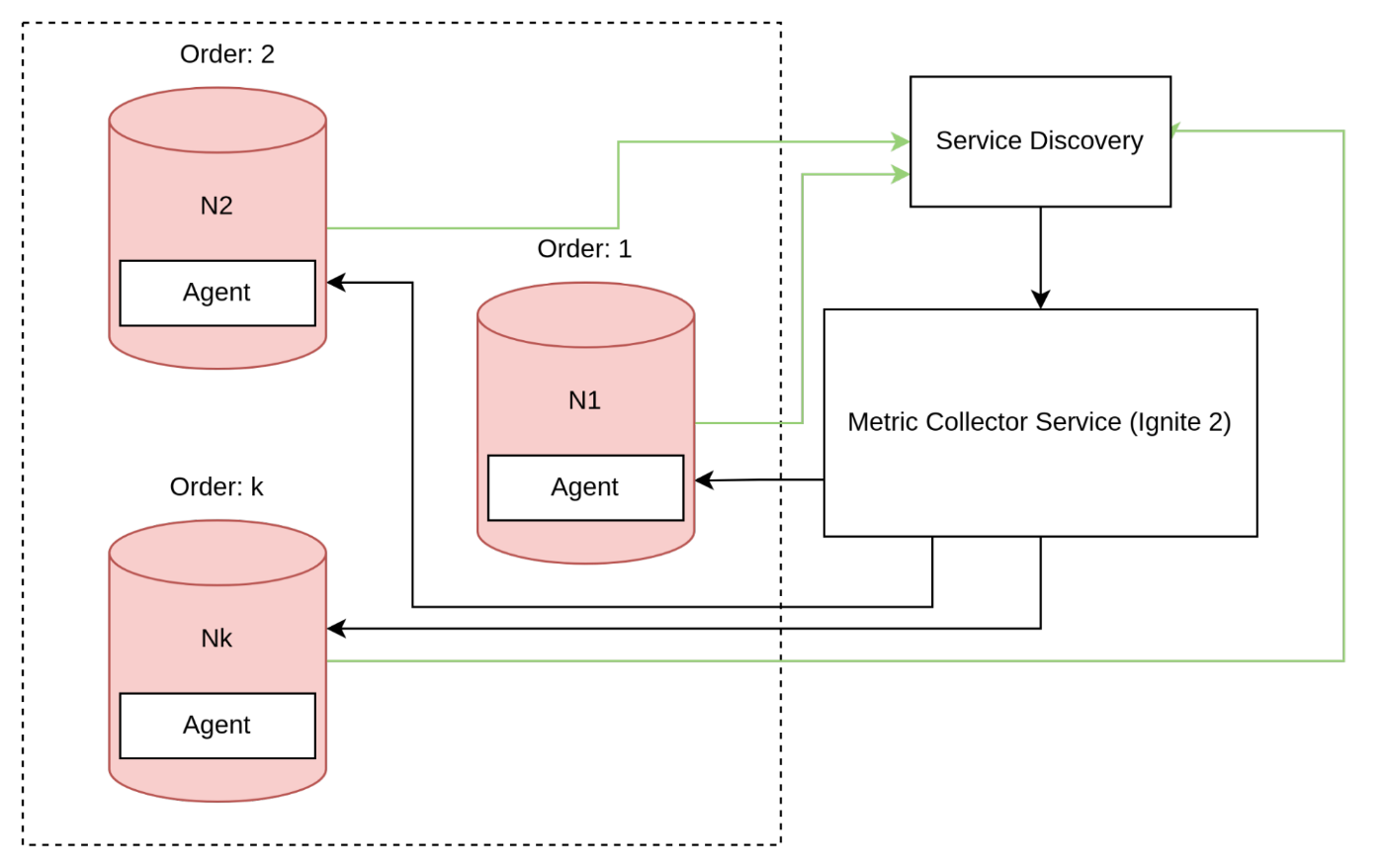
We can make this solution simpler by using the reverse connection as seen in the example, but it would require managing several connections which makes it more complex compared to the push approach.
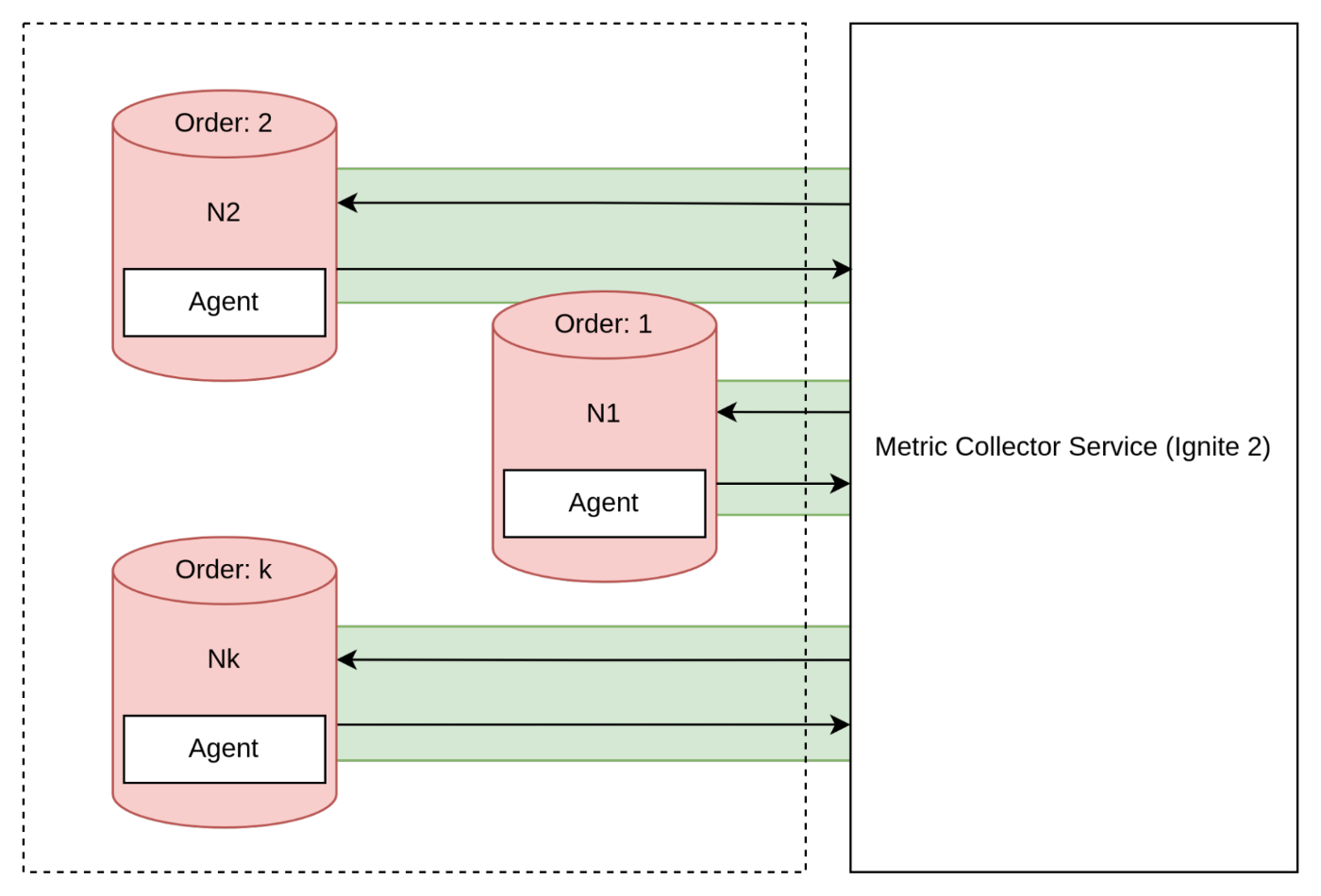
Furthermore, it's important to consider situations where the cluster is still functioning, but certain nodes are unable to establish a connection with the collector.
Single coordinators and followers
The following methods are similar to the push/pull methods discussed above, but with a slight difference. In this case, there is a single node in the cluster that acts as the coordinator agent, which establishes a connection with the metric collector and collects intermediate metrics from other nodes.
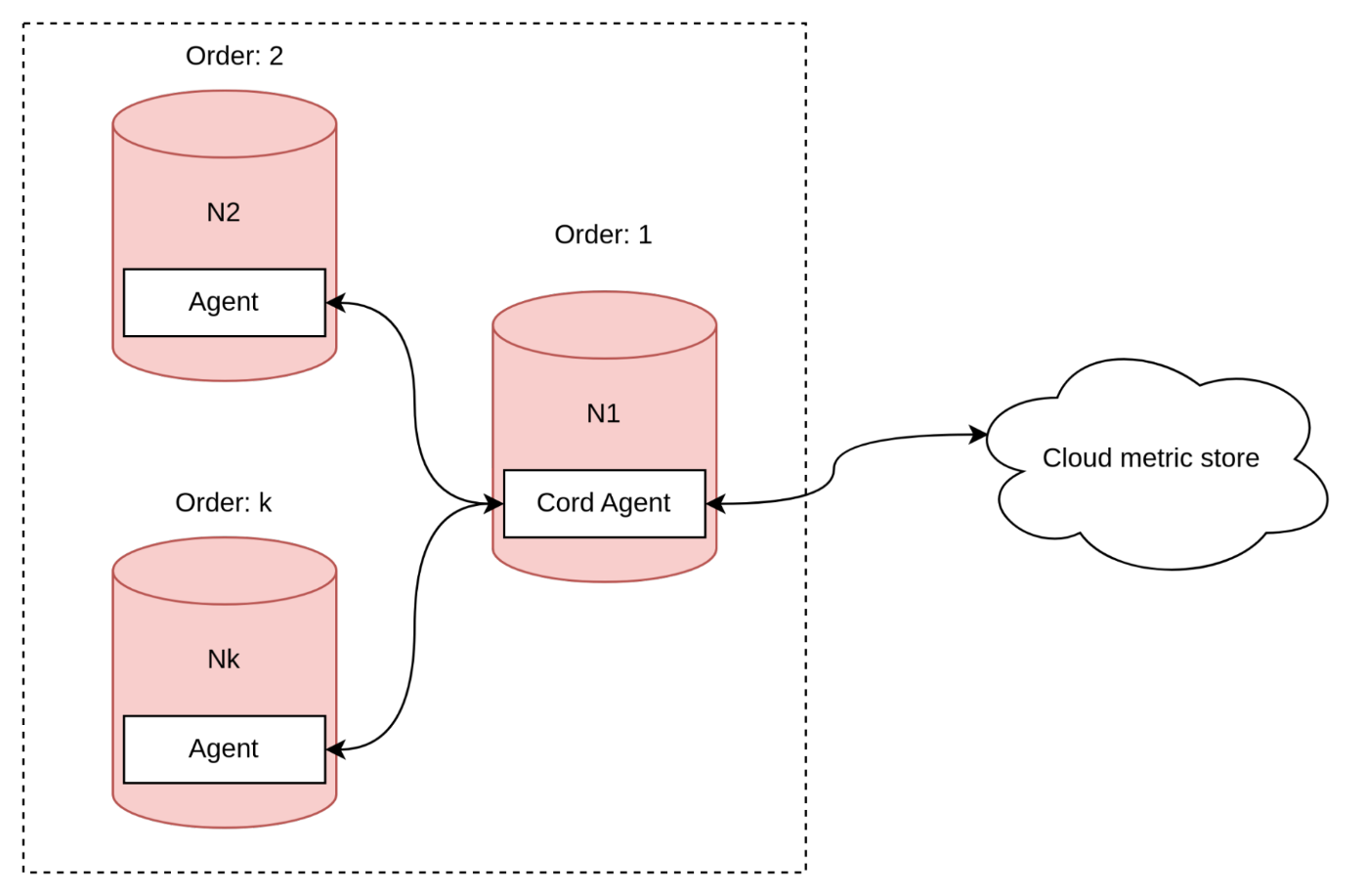
This method is simpler in terms of managing connections and synchronizing data based on timestamps, but like previous approaches, it has its disadvantages.
- Firstly, it may result in increased traffic consumption since metrics are submitted twice.
- Secondly, there is a possibility of running out of memory if the coordinator receives many batches.
- Lastly, managing split-brain scenarios may be more challenging.
Our solution
As I mentioned earlier, we chose to use an agent inside for our solution despite its disadvantages. This approach allows us to delegate split-brain problems to the cluster. Let's consider a scenario where the coordinator node splits the cluster.
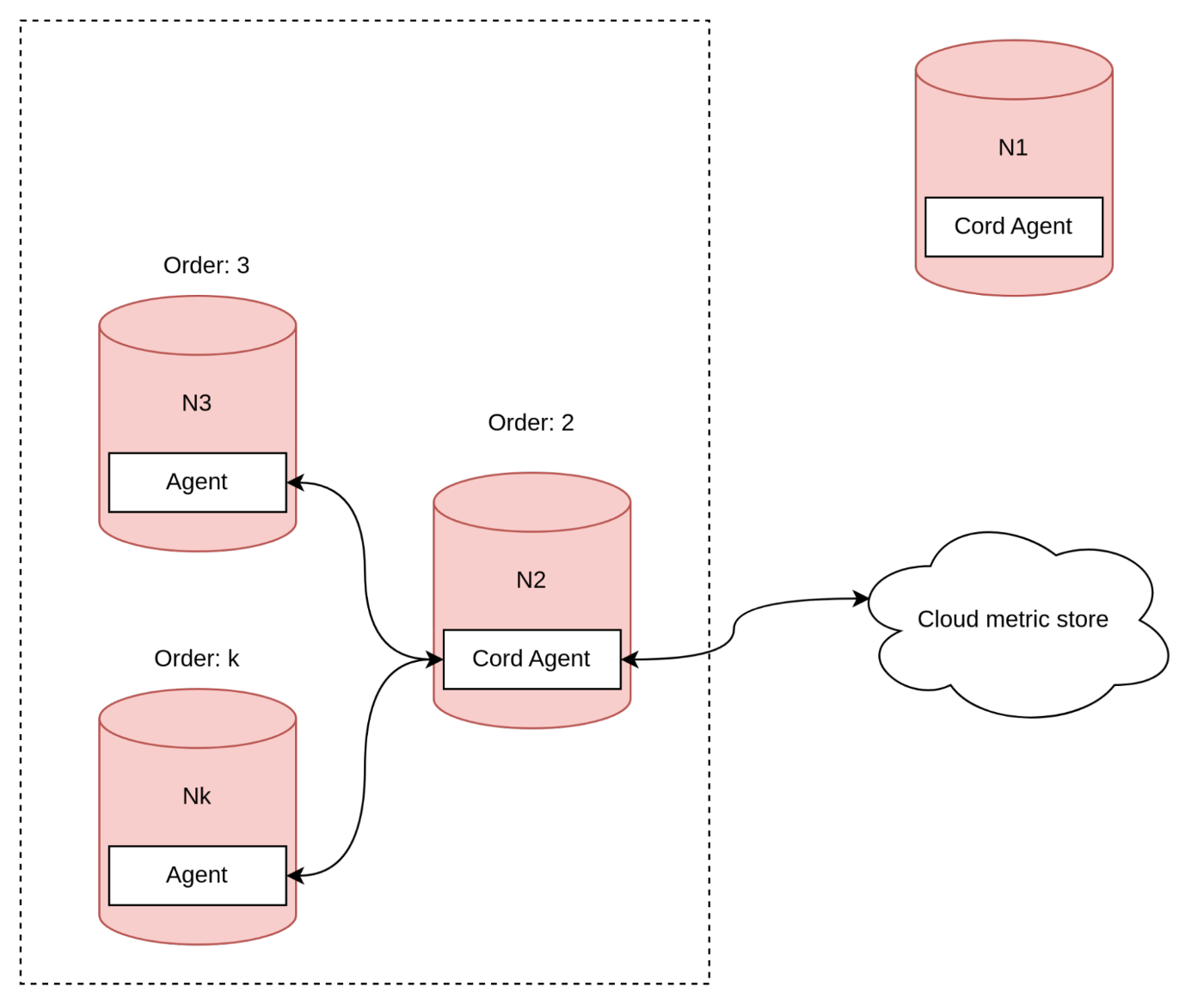
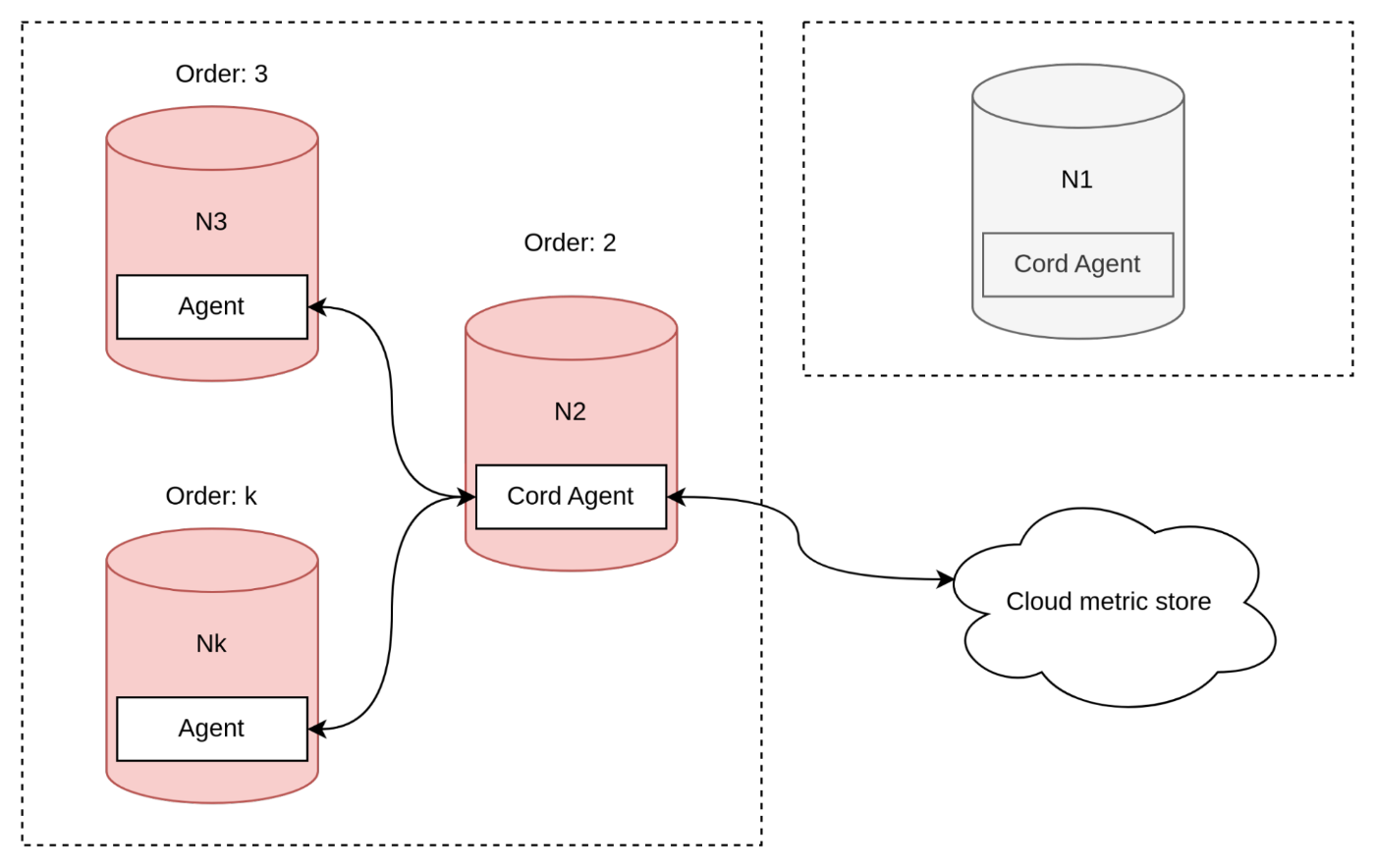
To handle the split-brain problem in our solution where we use an agent inside, we have decided to delegate the responsibility to the cluster. In the case where the coordinator node splits from the rest of the cluster, a new coordinator agent must be selected. However, selecting the new agent coordinator is not a trivial task. Our algorithm selects the oldest available node as the new agent coordinator, with the assumption that the cluster guarantees that the oldest node will be in the correct split section.
Protocols
When we return back to the simple diagram, there is one aspect that has not been discussed yet - the communication protocol.

Open telemetry
In my view, it would be best to use widely accepted industry standards such as Open telemetry for communication protocols. Although it may not be a perfect solution, it offers several advantages, such as:
- Not having to worry about implementing adapters for popular collection systems.
- The protocol is based on best practices.
However, it's worth noting that these common solutions may not be optimal for every unique scenario.
Rest / Graph QL / Sql like
Also the popular type of protocol is Rest, the benefit of this approach is that it is simple to use and check. For example via browser.
Custom protocol (Hand made - TCP / UDP, Protobuff)
Hand-made protocol can solve specific corner cases better because the developers have knowledge of the monitoring systems used. However, the downside is that it requires support for multiple adaptors if using other collector systems, and there is a risk of making the same mistakes that have already been solved in industry-standard protocols.
Our choice
In our discussions, we found that the main issues with our system design requirements were the large message size for full fetching and the need to keep schema values updated. Therefore, we ultimately decided to implement our own custom protocol.
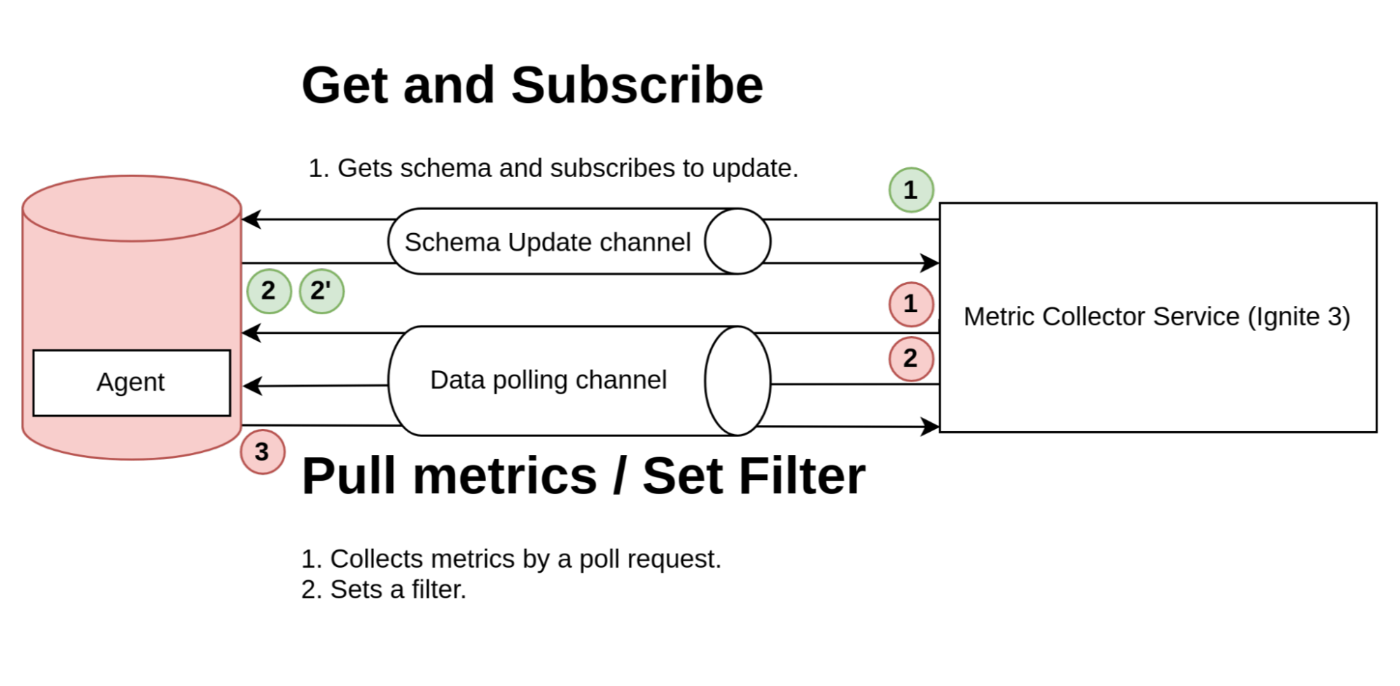
This protocol was described in the previous section.
Conclusion
To summarize, I tried to address the basic questions that were raised during the development process.