

Authors:
(1) Nir Chemaya, University of California, Santa Barbara and (e-mail: [email protected]);
(2) Daniel Martin, University of California, Santa Barbara and Kellogg School of Management, Northwestern University and (e-mail: [email protected]).
Table of Links
- Abstract and Introduction
- Methods
- Results
- Discussion
- References
- Appendix for Perceptions and Detection of AI Use in Manuscript Preparation for Academic Journals
Abstract
The emergent abilities of Large Language Models (LLMs), which power tools like ChatGPT and Bard, have produced both excitement and worry about how AI will impact academic writing. In response to rising concerns about AI use, authors of academic publications may decide to voluntarily disclose any AI tools they use to revise their manuscripts, and journals and conferences could begin mandating disclosure and/or turn to using detection services, as many teachers have done with student writing in class settings. Given these looming possibilities, we investigate whether academics view it as necessary to report AI use in manuscript preparation and how detectors react to the use of AI in academic writing.
1 Introduction
There is both excitement and concern about the impact that artificial intelligence (AI) could have on our world. In academia, this has inspired an explosion of research around AI. Some researchers are leveraging AI to help in answering research questions; for example, as a tool for performing statistical or textual analyses (e.g., Mullainathan and Spiess 2017, Athey and Imbens 2019, Fudenberg and A. Liang 2019, Farrell, T. Liang, and Misra 2020, Rambachan et al. 2021, Björkegren, Blumenstock, and Knight 2022, Capra, Gomies, and Zhang 2023, Franchi et al. 2023, Salah, Al Halbusi, and Abdelfattah 2023), or for the design or implementation of experiments (e.g., Beck et al. 2020, Charness, Jabarian, and List 2023, Horton 2023). Others have focused more on the interaction of humans with AI systems (e.g., Dietvorst, Simmons, and Massey 2015, Deza, Surana, and Eckstein 2019, Gajos and Mamykina 2022, Steyvers et al. 2022, Sundar and Lee 2022, Tejeda et al. 2022, Wang, C. Liang, and Yin 2023, Yang, M. Palma, and A. Drichoutis 2023) and the larger societal ramifications of AI (e.g., Agrawal, Gans, and Goldfarb 2019, Lambrecht and Tucker 2019, Obermeyer et al. 2019, Yang, M. A. Palma, and A. C. Drichoutis 2023, Chien et al. 2020, Rolf et al. 2020, Zuiderwijk, Chen, and Salem 2021, Pallathadka et al. 2023, Ray 2023, H. Singh and A. Singh 2023).
In terms of societal ramifications, one topic of interest is how AI will impact academia itself, especially given the emergent abilities of Large Language Models (LLM), which power tools like ChatGPT and Bard. Most of this research has centered on student use of AI to complete course or degree requirements (e.g., Cowen and Tabarrok 2023, Daun and Brings 2023, Fyfe 2023, Ibrahim et al. 2023, Jungherr 2023, Malik et al. 2023, Schmohl et al. 2020, Shahriar and Hayawi 2023). However, there has been less focus on the impact that AI is having and might have on manuscript preparation for academic journals, even though the impact this could have on science, and the propagation of scientific results, is potentially large.
An exception is Korinek (2023), who documents several use cases for LLMs for researchers, including academic writing. He notes, “LLMs can edit text for grammatical or spelling mistakes, style, clarity, or simplicity.” As a result, this class of tools “allows researchers to concentrate their energy on the ideas in their text as opposed to the writing process itself.” In particular, “this set of capabilities are perhaps most useful for non-native speakers who want to improve their writing.” The potential impact of these tools is validated by the emergence of companies that help academics leverage LLM in their writing. Some of those initiatives are even run by professors from academia, such as online workshops that teach researchers how to use ChatGPT for academic publishing.
However, an emerging set of papers (e.g., Altmäe, Sola-Leyva, and Salumets 2023, Thorp 2023, Shahriar and Hayawi 2023 and Hill-Yardin et al. 2023) detail some practical and ethical concerns with the use of these tools in preparing manuscripts for academic journals. For example, AI can generate a text with mistakes, including incorrect math, reasoning, logic, factual information, and citations (even producing references to scientific papers that do not exist). There are many welldocumented examples where LLM’s “hallucinate” and provide completely fictitious information. On top of this, these tools may also produce text that is biased against particular groups. These issues are exacerbated by the “black box” nature of LLM suggestions, meaning that we lack an understanding of how they work (e.g., Bommasani et al. 2021). Given these issues, liabilities arise when authors submit papers without fully vetting the text generated by LLMs. In addition, given that they are trained on a corpus of other writing and not the author’s own writing, using the output of tools like ChatGPT and Bard without proper attribution could be considered plagiarism.
Because of these concerns, authors may voluntarily choose to disclose whether they have used LLMs in preparing their manuscripts, as suggested by Bom (2023). However, given well-documented failures of disclosure in the field and lab (e.g., Dranove and Jin 2010, Jin, Luca, and Martin 2015), journals, conferences, and associations may respond by mandating disclosure through reporting requirements, as is already done for conflict-of-interest issues. For example, Elsevier limits the use of AI by authors “only to improve the language and readability of their paper” and requires “the appropriate disclosure... at the bottom of the paper in a separate section before the list of references.” See Table 6 in Appendix B for a list of major publishers who have voluntary and mandatory disclosure policies for AI use. To enforce these reporting requirements, journals, conferences, and associations might turn to using detection services, as many teachers have done with student writing in class settings. The use of LLMs in writing is potentially detectable because as Korinek (2023) notes, “Some observe that [LLM writing] is, naturally, a bit sterile and lacks the idiosyncrasies and elements of surprise that characterize human writing – a feature that detectors of LLM-written text zero in on.”
Given these looming possibilities, we investigate whether academics view reporting AI use in manuscript preparation as necessary and how detectors react to the use of AI in manuscript preparation. We first conducted a survey of academics in which we elicited perceptions about reporting assistance in manuscript preparation. We then used GPT-3.5 to revise abstracts from the past 10 years of Management Science by asking the software program to either fix grammar or rewrite text. Finally, we ran the original abstracts and revised abstracts through a leading paid AI detection service.
We have three main findings. First, as shown partially in Figure 1, the academics we surveyed were less likely to think that using AI to fix the grammar in manuscripts should be reported than using AI to rewrite manuscripts, but detection software did not always draw this distinction, as abstracts for which GPT-3.5 was used to fix grammar were often flagged as having a high chance of being written by AI. Second, we found little difference in preferences for reporting ChatGPT and research assistant (RA) help, but significant differences in reporting preferences between these sources of assistance and paid proofreading and other AI assistant tools (Grammarly and Word). Third, we found disagreements among the academics we surveyed on whether using ChatGPT to rewrite text needs should be reported, and differences were related to perceptions of ethics, academic role, and English language background.
The rest of the paper is structured as follows. Section 2 introduces our survey design and our method for testing ChatGPT use with AI detection algorithms. Section 3 shows our main results. Finally, section 4 discusses some limitations of our work, open questions arising from our results, and suggestions for future research.
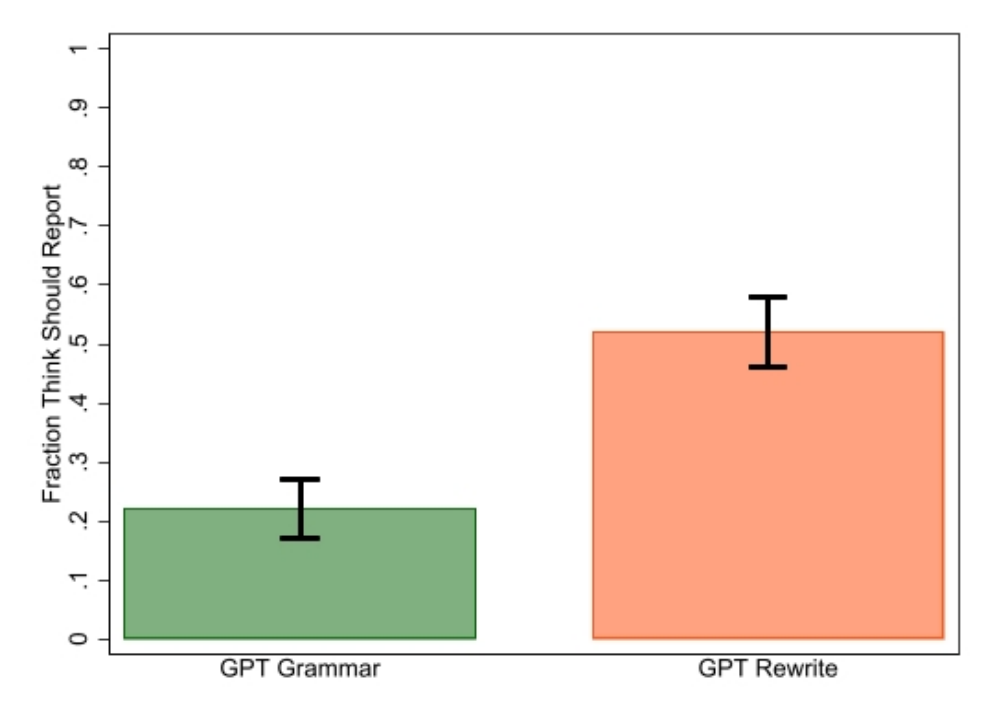
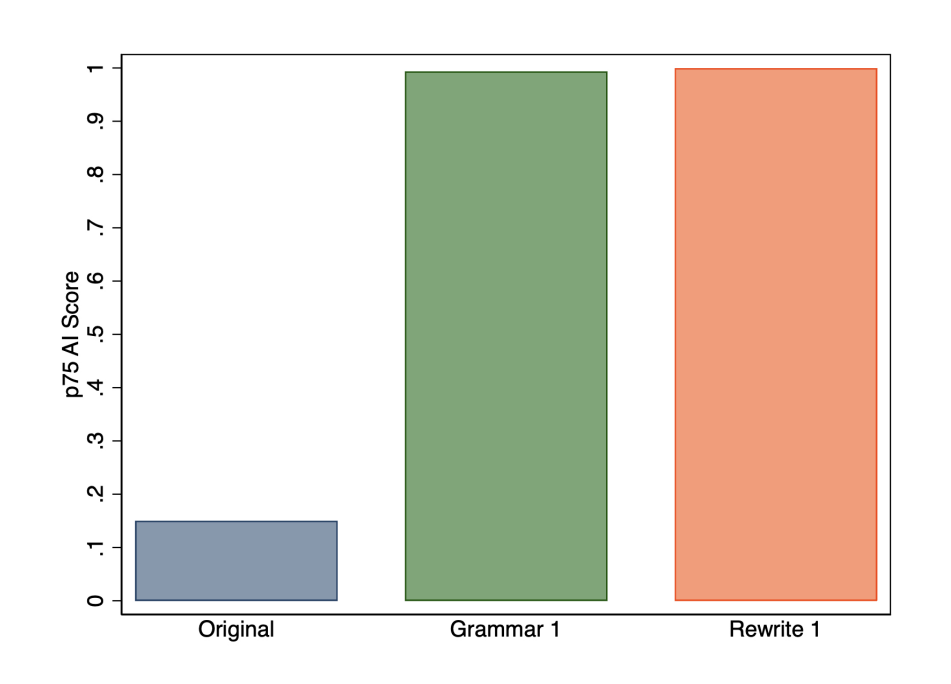
Figure 1: Reporting views (a) vs. detection results (b).
This paper is available on arxiv under CC 4.0 license.