
Authors:
(1) Omid Davoodi, Carleton University, School of Computer Science;
(2) Shayan Mohammadizadehsamakosh, Sharif University of Technology, Department of Computer Engineering;
(3) Majid Komeili, Carleton University, School of Computer Science.
Table of Links
Interpretability of the Decision-Making Process
The Effects of Low Prototype Counts
Prototype Interpretability
Our first set of experiments had the goal of finding out the interpretability of the prototypes created by each method. Many part prototype methods claim that their prototypes are intrinsically interpretable. In that case, humans should be able to understand the concept that is encoded within those prototypes. If a prototype represents a large area of an image without any coherent concept understandable to humans, it is not an interpretable prototype.
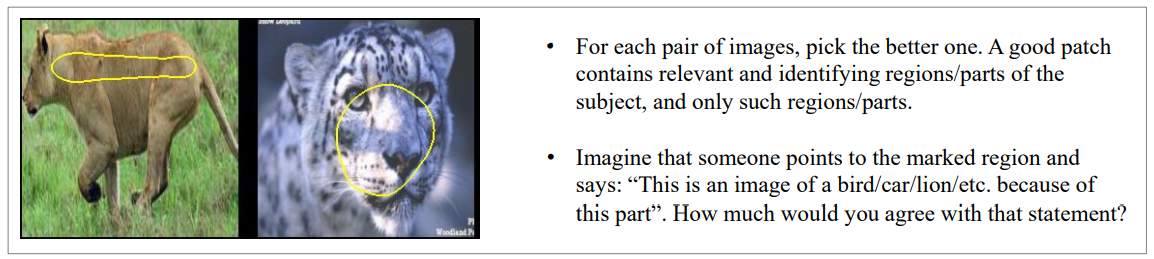
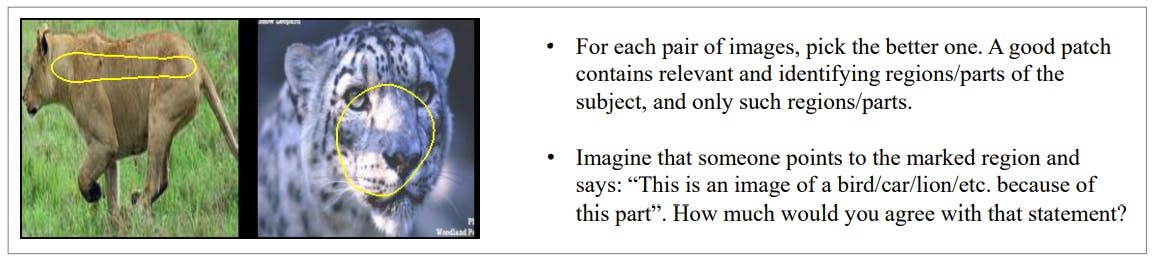
In the first experiment, each person was shown a pair of prototypes (concept images in the case of ACE) on the same dataset coming from different methods. The annotators had to choose the prototype they found more interpretable out of the two. Every person had to complete 10 such pairs each time. Out of those 10, 2 were validation pairs handpicked by us to ensure answer quality. An example of such a pair and the instructions given to each person are show in Figure 4.
Only people who had finished a qualification task consisting of 7 such pairs with perfect scores were allowed into the main study. Moreover, each 10-pair set of query samples was given to three different people to gauge overall agreement and find individuals who might have chosen randomly. Additionally, this experiment was repeated 3 times and the results were aggregated.
This experiment was a purely comparative study between different methods. This ensured that people had a frame of reference when deciding which method worked better, and this is a common practice in many studies of subjective nature. But they are not without problems. One of the more important problems with this experiment was that it could not answer whether the prototypes from these methods were interpretable or not. It could only answer whether the prototypes of a particular method were more interpretable on average than the ones from another.
To remedy this, we conducted another set of experiments. In the new absolute experiments the annotators were given the option to also choose "Both" and "None" if they thought that both or none of the images in the pair were interpretable. The reason we did not simply show them a single image asking for interpretability was to keep the layout of the experiments very similar. This not only simplified the logistics of creating query samples for the new experiment, but also gave us the opportunity to see whether the rankings of the methods seen in the comparative experiments remained the same when the new options were added. The assumption was that if a very similar experiment with those options added resulted in a drastic change in the rankings, it would reveal problems in our methodology that were hidden beforehand. Instructions given to each person were as follows:
• For each pair of images, pick the one with the best highlighted patch. A good patch contains relevant and identifying regions/parts of the subject, and only such regions/parts.
• If both images have good or bad patches, select "Both" or "None" respectively.
• Imagine that someone points to the marked region and says: "This is an image of a bird/car/lion/etc. because of this part“. How much would you agree with that statement?
It is important to note that new image pairs were created for this experiment. This was again to see if a new set of data changes the rankings considerably, revealing any potential hidden problems with the statistical significance of the results. A new qualification task and a validation set were also created. The rest of the setup was almost identical to the comparative experiment. Each time, the annotator was given 10 prototype image pairs and told to pick the best option for each pair, with two out of those 10 pairs coming from the validation set. The experiment was repeated 4 times and the results were aggregated.

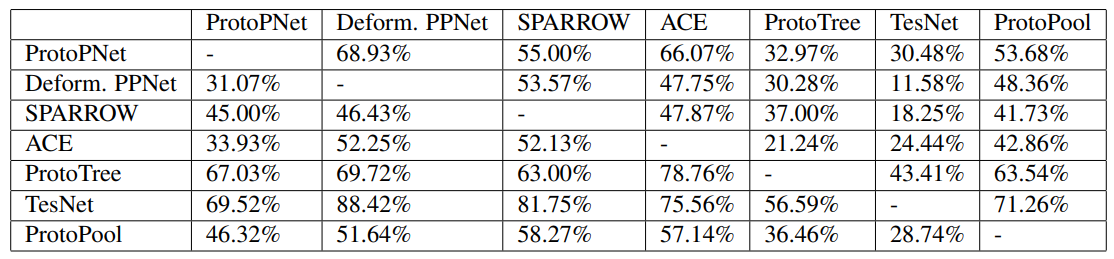
In total, 1104 pairs were compared and annotated by humans for the comparative study. Table 1 shows the percentage of times each method was chosen against others. As can be seen, prototypes selected by TesNet were chosen 73.26% of the time when compared to prototypes selected by other methods. In the second place was ProtoTree with 63.64% preference. It is also interesting to note the relative weakness of SPARROW and Deformable ProtoPNet.
Table 2 shows the results of the same experiments but on a method-by-method basis. Each element of the table shows the results of the pairwise comparison between the two methods, with the method shown in the first column being the one selected out of the two. For example, the intersection between the row "ACE" and the column "ProtoPool" shows the percentage of times (42.86%) ACE was chosen against ProtoPool in the experiments. While there is more variation when looked at with this much detail, the general trends hold true.

For the absolute experiments, 1304 pairs were compared and annotated by humans in total. Table 3 shows the percentage of times each method’s prototypes were chosen in general. As the options for "Both" and "None" also existed in this experiment, the results here show the percentage of prototypes from each method that the annotators found acceptable. While the overall rankings seem to have mostly remained the same, the higher percentages overall show that while some methods might lose in the comparative study, their prototypes are still interpretable, even if a bit less so than the more successful methods. These results also show that 95.18% of the prototypes created by TesNet and 89.56% of the ones by ProtoTree are seen as interpretable. These results match our own observations, where it seems that TesNet and ProtoTree offer consistently good prototypes in all of the datasets.
Like before, Table 4 shows the results of the same experiments but on a method-by-method basis. Each row shows the percentage of times a method (shown on the first column) was selected either solely or as part of the "Both" option when paired with another method shown on the top row. Note that this time, the sum of mirrored cells does not necessarily add up to 100% due to the existence of "Both" and "None" options. The results show a fine-grained consistency in prototype interpretability rates across all methods.
This paper is available on arxiv under CC 4.0 license.