
Authors:
(1) Omid Davoodi, Carleton University, School of Computer Science;
(2) Shayan Mohammadizadehsamakosh, Sharif University of Technology, Department of Computer Engineering;
(3) Majid Komeili, Carleton University, School of Computer Science.
Table of Links
Interpretability of the Decision-Making Process
The Effects of Low Prototype Counts
Interpretability of the Decision-Making Process
Our final experiment was designed to assess the interpretability of the decision-making process. In general, part-prototype methods offer a set of explanations for a decision and then use those concepts for a final classification step, which is usually a fully connected layer. We designed our framework for cases where the final decision is made using such a final layer over all of the prototype activations and so we tried to stay as faithful as possible to the actual decision-making process. This meant that we had to make sure we included the activation scores and rankings of the prototypes in the experiment design.
ACE is not a classification method and there is no final decision to make. As a result, ACE, alongside ProtoTree, is not included in this experiment. In the case of ProtoTree, the method uses a decision-tree structure to offer its explanations. This is not compatible with our experiment design. Moreover, the agreement and distinction tests designed by HIVE[12] are adequate for evaluating the interpretability here as they use the same tree structure as the method itself. In the end, the authors of HIVE found that the tree structure was interpretable by humans. This cannot be said for the remaining five methods.


A challenge in interpretability is to show enough information to humans so that they can understand the process without overwhelming them. For example, we cannot expect a human to look at the entire 2000 prototypes and their activations in order to understand how ProtoPNet classifies a query image from the CUB dataset. Many part-prototype models seem to have opted to use the 10 most activated prototypes for a particular query image as a good proxy for the entire model9, 18, 20. 10 prototypes are much more manageable for a human to understand than 2000, but we have to make sure that they are also a good proxy for the model itself.
If the model, using those same 10 prototypes, is able to classify the query image and come to the same decision as before (regardless of whether that original decision was correct or not), then those 10 prototypes are a good proxy for the decision-making process of the model for that particular query image. This implies that the model selectively utilizes a limited number of prototypes from its extensive pool to categorize images.
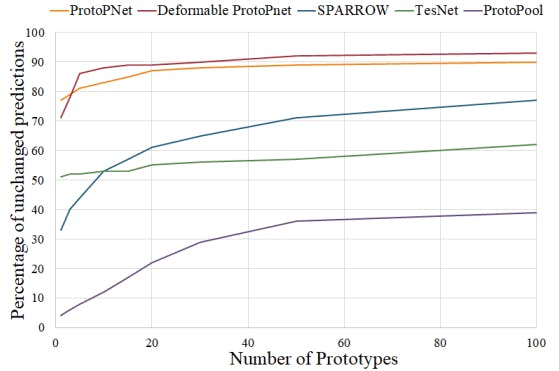
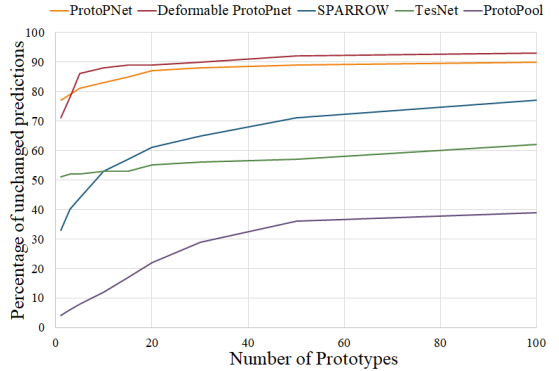
This is unfortunately not always the case. For some query images, the model might use more than 10 prototypes to come up with its final decision. In those cases, we can argue that the interpretability of the method will suffer, as it relies on a higher number of prototypes, which, in turn, can overwhelm humans. As a result, finding out the model’s accuracy with only a limited number of prototypes can be a good indicator of the interpretability of the decision-making process. We performed experiments where we only kept the top 1, 3, 5, 10, 15, 20, 30, 50, and top 100 prototypes for each method on the CUB dataset, and For each reduced model, we calculated the percentage of its decisions that agree with the decisions of the model that uses the complete prototype set. The results of these can be seen in Figure 7.
As can be seen, not all methods are equal in this regard. Some like ProtoPNet and Deformable ProtoPNet can achieve the same decisions using relatively few prototypes. Others like ProtoPool utilize a large amount of prototypes to classify most of the query images. Only 12% of the decisions of ProtoPool remain the same when only the 10 top prototypes are kept. This observed low percentage is concerning especially as it only goes up to 39% after using 100 prototypes out of the 202 prototypes this model had for the CUB dataset.
After this step, we classified the same query samples utilized in the previous experiments using our models but only kept the ones where the decision of the model did not change after keeping only the 10 top activated prototypes. For each of these query images that passed this filter, we then gathered the top 10 prototypes and their activation regions on the query image into an explanation set. The prototypes in this explanation set were sorted from the highest activation to the lowest. As the activation values themselves might be different for each query image and might not mean anything to a human, we used a confidence system where the top activated prototype has a relative confidence level of 100% and every other prototype has its confidence level scaled by its activation value compared to the activation value of the top prototype. We then included the class label associated with that prototype in the explanation set. In the case of ProtoPool which doesn’t have a single class associated with each prototype, we picked the 3 top classes associated with that prototype. These classes were obfuscated with numbers so that the role of prior human knowledge could be reduced. Examples of these explanation sets can be found in Figure 8. We then asked our human participants on Amazon Mechanical Turk to guess the class that was picked for that query image by our classifier model. Our instructions for the AMT participants were as follows:
• Given a photo of an animal or a car (Query), an AI is predicting the species or the model of the subject of the photo using prototypes it has learned from previously seen photos. Specifically for each prototype, the AI identifies a region in the photo (Query) that looks the most similar to a region (marked with a yellow border) in the prototype and rates its relative confidence in their similarity. Each prototype is associated with one, or multiple animal species/car models. The AI will pick the species/type based on how similar and frequent the prototypes are to the query.
• For each query, we show explanations on how the AI reasons the species of the animals or the model of the car. Looking at the species/model numbers for each query-prototype pair, guess the species/model number that you would think the AI predicted for the query.
• Guessing randomly will get you low overall accuracy depending on the number of options. You will only get rewards if your performance is sufficiently higher than random guesses.
• Remember that you can zoom-in/out and pan the image using the buttons below the image.
The idea behind this experiment is similar to that of the distinction task from HIVE. In order for a human to understand the decision-making process of an AI system, they should be able to correctly predict the decision of the AI system from the same information it uses.

In total, 607 explanation sets were shown to and annotated by the participants. Table 9 shows the percentage of query samples in which humans correctly predicted the predictions of the models. Apart from ProtoPool, human participants seem to be able to understand the underlying principles behind the final decision-making process of the rest of the methods. Prototypes in ProtoPool can belong to multiple classes and this causes severe issues with understanding how the method makes its decisions. The stark contrast between ProtoPool and the others shows that this evaluation criteria is a useful way of determining problems in the interpretability of Prototype-based methods.
This paper is available on arxiv under CC 4.0 license.