This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Andrey Zhmoginov, Google Research & {azhmogin,sandler,mxv}@google.com;
(2) Mark Sandler, Google Research & {azhmogin,sandler,mxv}@google.com;
(3) Max Vladymyrov, Google Research & {azhmogin,sandler,mxv}@google.com.
Table of Links
- Abstract and Introduction
- Problem Setup and Related Work
- HyperTransformer
- Experiments
- Conclusion and References
- A Example of a Self-Attention Mechanism For Supervised Learning
- B Model Parameters
- C Additional Supervised Experiments
- D Dependence On Parameters and Ablation Studies
- E Attention Maps of Learned Transformer Models
- F Visualization of The Generated CNN Weights
- G Additional Tables and Figures
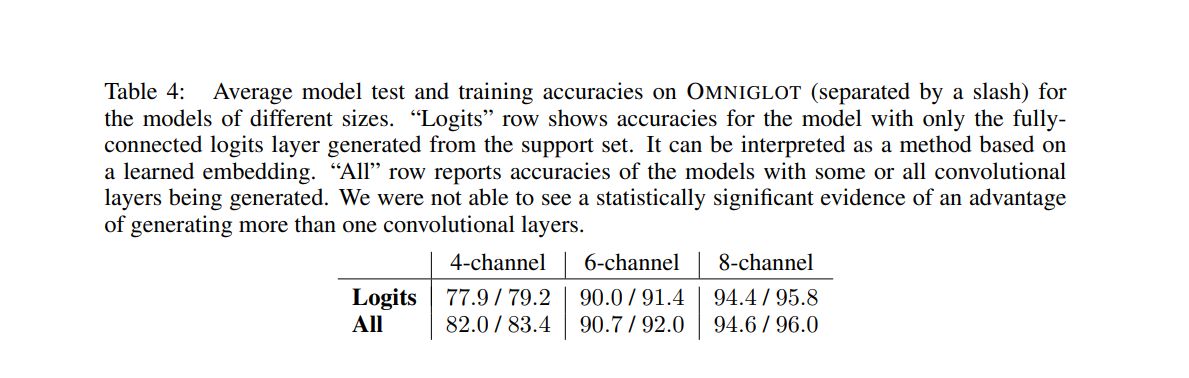
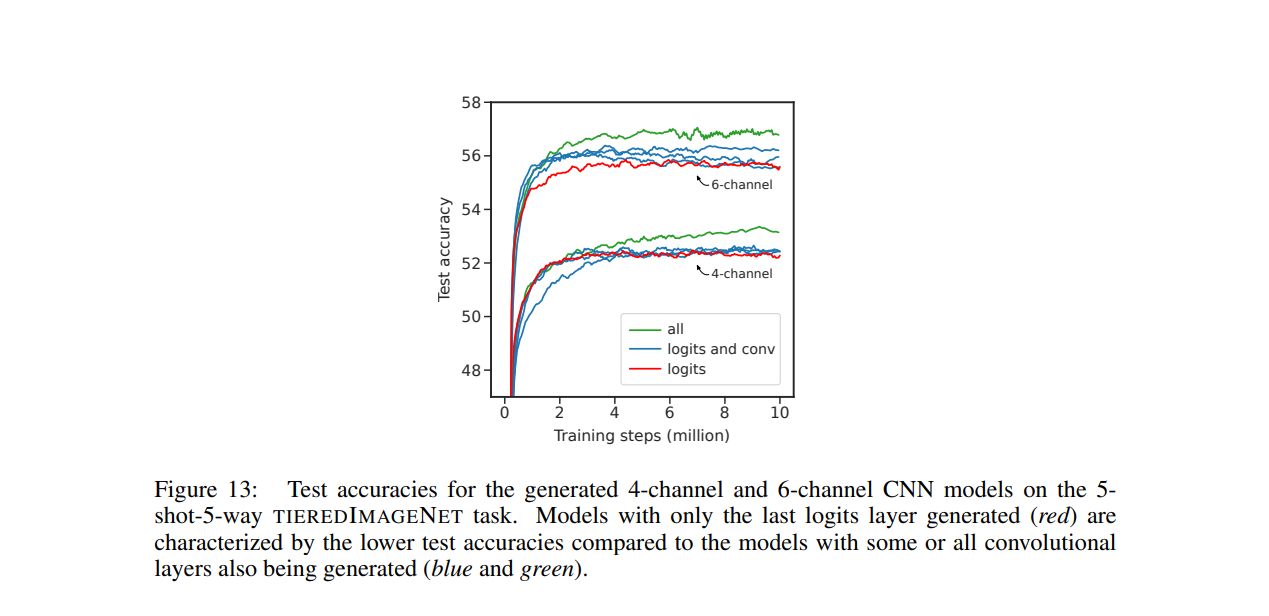
G ADDITIONAL TABLES AND FIGURES