

This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Andrey Zhmoginov, Google Research & {azhmogin,sandler,mxv}@google.com;
(2) Mark Sandler, Google Research & {azhmogin,sandler,mxv}@google.com;
(3) Max Vladymyrov, Google Research & {azhmogin,sandler,mxv}@google.com.
Table of Links
- Abstract and Introduction
- Problem Setup and Related Work
- HyperTransformer
- Experiments
- Conclusion and References
- A Example of a Self-Attention Mechanism For Supervised Learning
- B Model Parameters
- C Additional Supervised Experiments
- D Dependence On Parameters and Ablation Studies
- E Attention Maps of Learned Transformer Models
- F Visualization of The Generated CNN Weights
- G Additional Tables and Figures
3 HYPERTRANSFORMER
In this section, we describe our approach to few-shot learning that we call a HYPERTRANSFORMER (HT) and justify the choice of the self-attention mechanism as its basis.
3.1 FEW-SHOT LEARNING MODEL


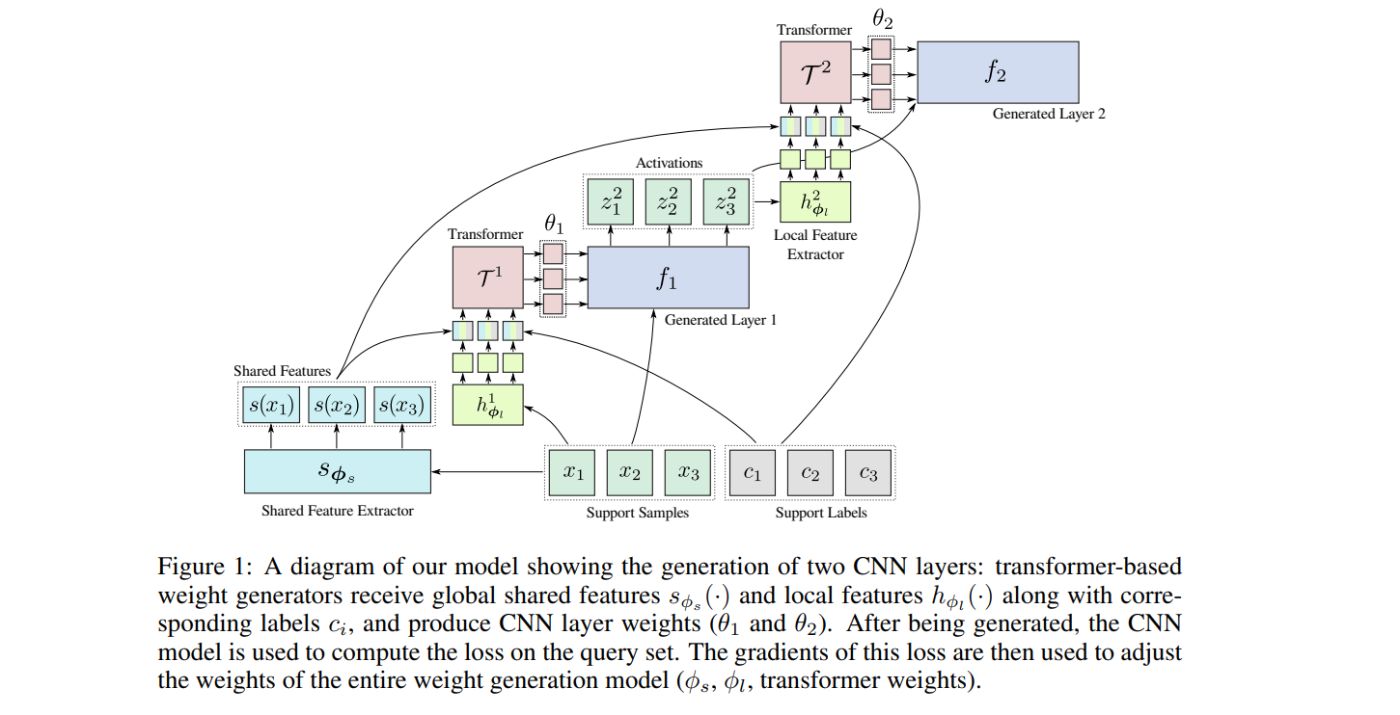
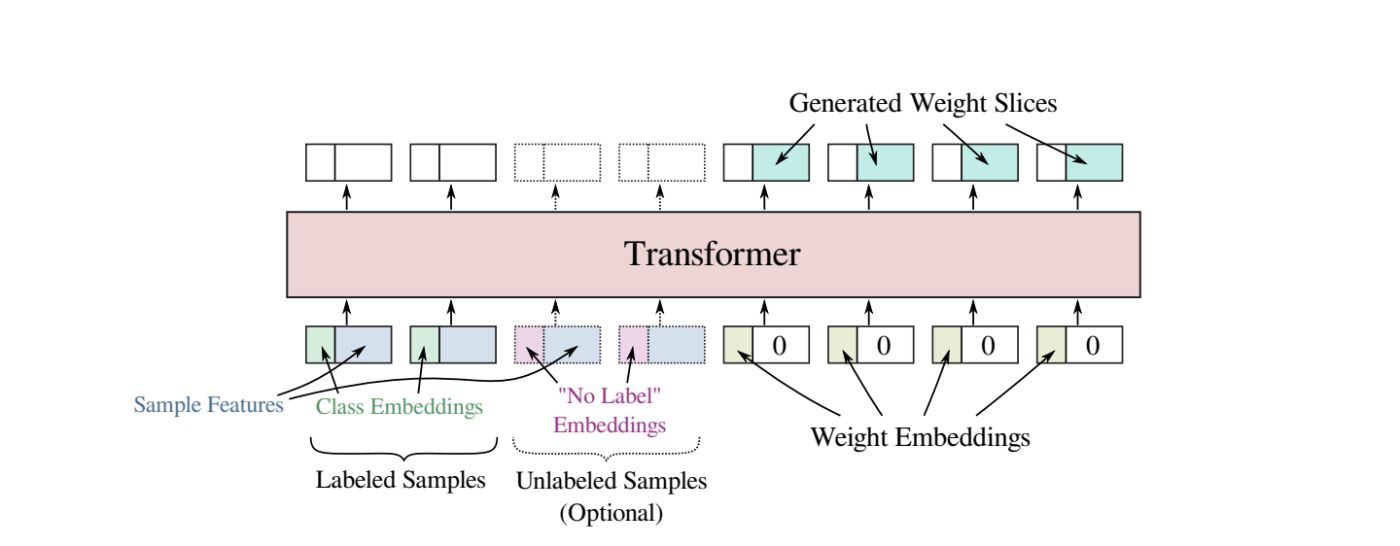
Along with the input samples, the sequence passed to the transformer was also populated with special learnable placeholder tokens, each associated with a particular slice of the to-be-generated weight tensor. Each such token was a learnable d-dimensional vector padded with zeros to the size of the input sample token. After the entire input sequence was processed by the transformer, we read out model outputs associated with the weight slice placeholder tokens and assembled output weight slices into the final weight tensors (see Fig. 2).

Training the model. The weight generation model uses the support set to produce the weights of some or all CNN model layers. Then, the cross-entropy loss is computed for the query set samples that are passed through the generated CNN model. The weight generation parameters φ (including the transformer model and shared/local feature extractor weights) are learned by optimizing this loss function using stochastic gradient descent.
3.2 REASONING BEHIND THE SELF-ATTENTION MECHANISM
The choice of self-attention mechanism for the weight generator is not arbitrary. One motivating reason behind this choice is that the output produced by generator with the basic self-attention is by design invariant to input permutations, i.e., permutations of samples in the training dataset. This also makes it suitable for processing unbalanced batches and batches with a variable number of samples (see Sec. 4.3). Now we show that the calculation performed by a self-attention model with properly chosen parameters can mimic basic few-shot learning algorithms further motivating its utility.
Supervised learning. Self-attention in its rudimentary form can implement a method similar to cosine-similarity-based sample weighting encoded in the logits layer[3] with weights W:

[3] here we assume that the embeddings e are unbiased, i.e., heii = 0
[4] in other words, the self-attention layer should match tokens (µ(i), 0) with (ξ(i), . . .).