

Table of Links
3.1. Benefits scale with model size and 3.2. Faster inference
3.3. Learning global patterns with multi-byte prediction and 3.4. Searching for the optimal n
3.5. Training for multiple epochs and 3.6. Finetuning multi-token predictors
3.7. Multi-token prediction on natural language
4. Ablations on synthetic data and 4.1. Induction capability
5. Why does it work? Some speculation and 5.1. Lookahead reinforces choice points
5.2. Information-theoretic argument
7. Conclusion, Impact statement, Environmental impact, Acknowledgements, and References
A. Additional results on self-speculative decoding
E. Additional results on model scaling behavior
F. Details on CodeContests finetuning
G. Additional results on natural language benchmarks
H. Additional results on abstractive text summarization
I. Additional results on mathematical reasoning in natural language
J. Additional results on induction learning
K. Additional results on algorithmic reasoning
L. Additional intuitions on multi-token prediction
3.7. Multi-token prediction on natural language
To evaluate multi-token prediction training on natural language, we train models of size 7B parameters on 200B tokens of natural language with a 4-token, 2-token and nexttoken prediction loss, respectively. In Figure 5, we evaluate the resulting checkpoints on 6 standard NLP benchmarks. On these benchmarks, the 2-future token prediction model performs on par with the next-token prediction baseline
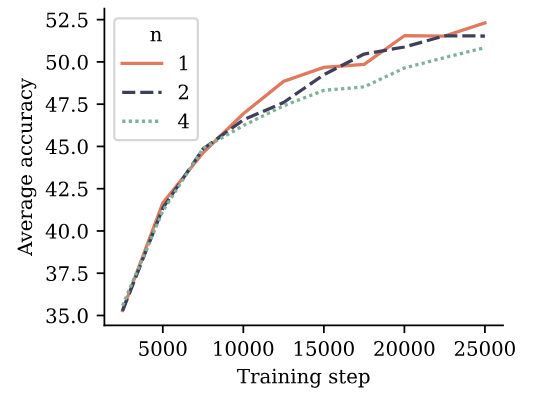
throughout training. The 4-future token prediction model suffers a performance degradation. Detailed numbers are reported in Appendix G.
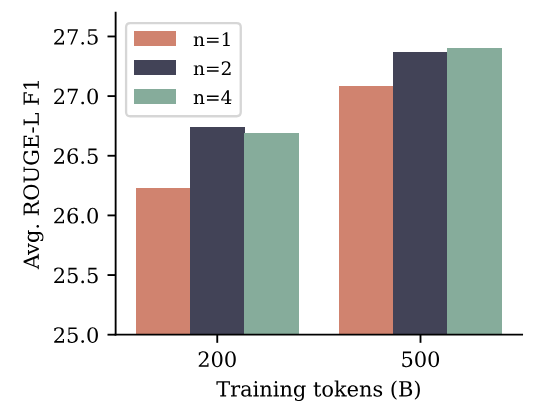
However, we do not believe that multiple-choice and likelihood-based benchmarks are suited to effectively discern generative capabilities of language models. In order to avoid the need for human annotations of generation quality or language model judges—which comes with its own pitfalls, as pointed out by Koo et al. (2023)—we conduct evaluations on summarization and natural language mathematics benchmarks and compare pretrained models with training sets sizes of 200B and 500B tokens and with next-token and multi-token prediction losses, respectively
For summarization, we use eight benchmarks where ROUGE metrics (Lin, 2004) with respect to a ground-truth summary allow automatic evaluation of generated texts. We finetune each pretrained model on each benchmark’s training dataset for three epochs and select the checkpoint with the highest ROUGE-L F1 score on the validation dataset. Figure 6 shows that multi-token prediction models with both n = 2 and n = 4 improve over the next-token baseline in ROUGE-L F1 scores for both training dataset sizes, with the performance gap shrinking with larger dataset size. All metrics can be found in Appendix H.
For natural language mathematics, we evaluate the pretrained models in 8-shot mode on the GSM8K benchmark (Cobbe et al., 2021) and measure accuracy of the final answer produced after a chain-of-thought elicited by the fewshot examples. We evaluate pass@k metrics to quantify diversity and correctness of answers like in code evaluations
and use sampling temperatures between 0.2 and 1.4. The results are depicted in Figure S13 in Appendix I. For 200B training tokens, the n = 2 model clearly outperforms the next-token prediction baseline, while the pattern reverses after 500B tokens and n = 4 is worse throughout.
This paper is available on arxiv under CC BY 4.0 DEED license.
Authors:
(1) Fabian Gloeckle, FAIR at Meta, CERMICS Ecole des Ponts ParisTech, and contributed equally;
(2) Badr Youbi IdrissiFAIR at Meta, LISN Université Paris-Saclay, and contributed equally;
(3) Baptiste Rozière, FAIR at Meta;
(4) David Lopez-Paz, FAIR at Meta and his the last author;
(5) Gabriel Synnaeve, FAIR at Meta and the last author.