
Table of Links
2 Related Work
2.1 Neural Codec Language Models and 2.2 Non-autoregressive Models
2.3 Diffusion Models and 2.4 Zero-shot Voice Cloning
3 Hierspeech++ and 3.1 Speech Representations
3.2 Hierarchical Speech Synthesizer
4 Speech Synthesis Tasks
4.1 Voice Conversion and 4.2 Text-to-Speech
5 Experiment and Result, and Dataset
5.2 Preprocessing and 5.3 Training
5.6 Zero-shot Voice Conversion
5.7 High-diversity but High-fidelity Speech Synthesis
5.9 Zero-shot Text-to-Speech with 1s Prompt
5.11 Additional Experiments with Other Baselines
7 Conclusion, Acknowledgement and References
3.2 Hierarchical Speech Synthesizer
We propse a hierarchical speech synthesizer as the backbone speech synthesizer for HierSpeech++. We can train this module using only speech data without any labels such as speaker id and text transcripts. Building on HierVST, we significantly improved the model for human-level audio quality and zero-shot style transfer, as illustrated in Fig 2.
3.2.1 Dual-audio Acoustic Encoder
Although previous models successfully increased the acoustic capacity by replacing the Mel-spectrogram with a linear spectrogram, the autoencoder that is trained by minimizing a KL divergence has shown low reconstruction quality in terms of PESQ, Mel-spectrogram distance, pitch periodity, and voice/unvoice F1 score. This may reduce a perceptual quality in zero-shot voice cloning. To address the limitations of using linear spectrogram and improve the perceptual quality, we introduce a dual-audio acoustic encoder designed to capture a more comprehensive and richer acoustic representation. We add a waveform encoder for distilling information from the raw waveform audio and concatenate a representation from waveform audio with a representation from a linear spectrogram. Finally, the acoustic representation is projected from a concatenated representation.
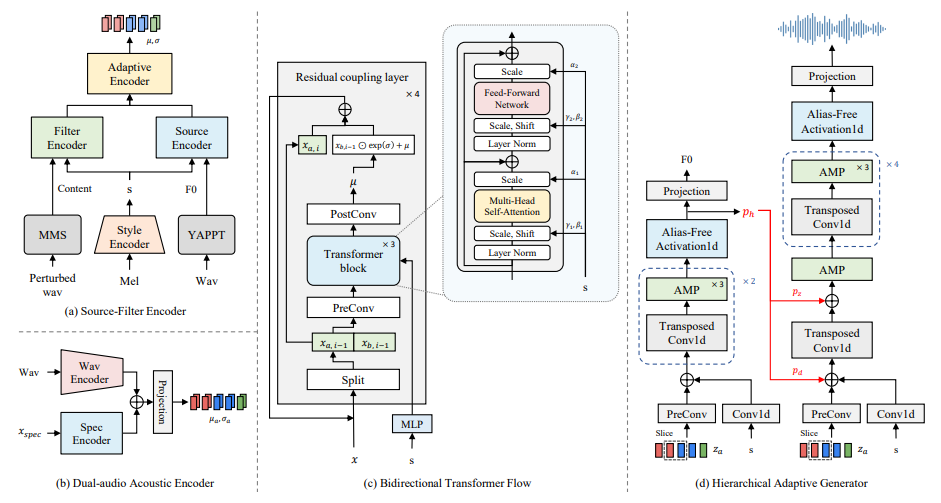
3.2.2 Source-filter Multi-path Semantic Encoder
Following HierVST, we also utilize a multi-path selfsupervised speech representation for speaker-related and speaker-agnostic semantic representations. Each representation is used as a prior for hierarchical style adaptation. We extract semantic representations from the middle layer of MMS to obtain linguistic information1 . We also utilize a fundamental frequency (F0) to improve speech disentanglement for enhanced prior, which enables a manual control of the pitch contour. For speaker-agnostic semantic representation, we utilize a speech perturbation to remove speaker-related information from the self-supervised speech representation. For speaker-related semantic representation, we do not use speech perturbation to reduce the gap between semantic and acoustic representation
3.2.3 Hierarchical Variational Autoencoder

1. Specifically, we utilize the representation from the seventh layer of MMS.
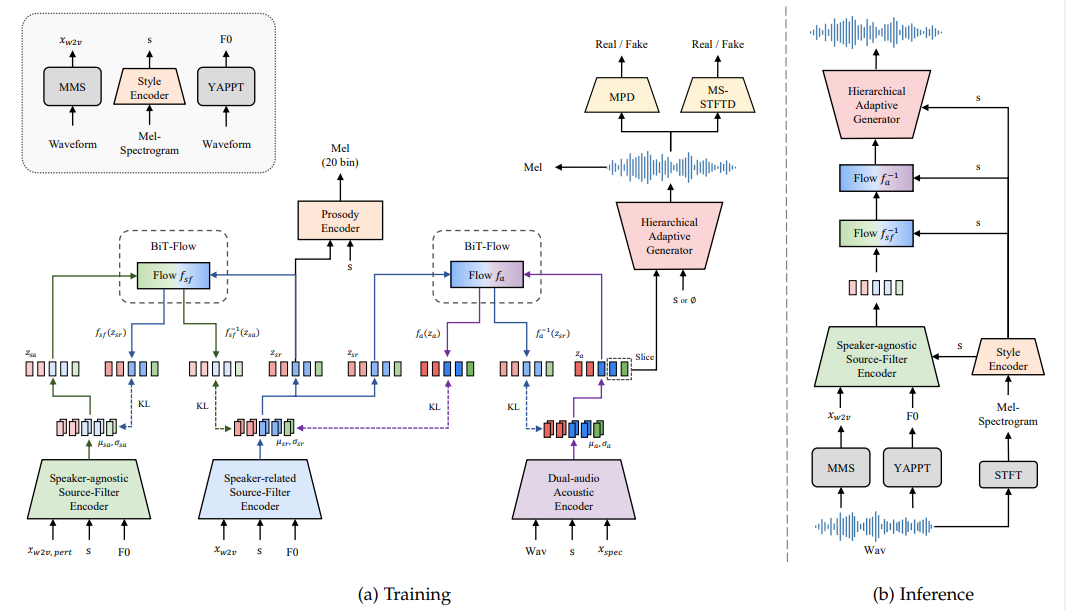
conditional information c to hierarchically generate waveform audio. In addition we use an enhanced linguistic representation from the self-supervised representation of the original waveform, which is not perturbed. Moreover, the raw waveform audio is reconstructed from the acoustic representation which is extracted using a linear spectrogram and waveform audio during training. To connect the acoustic and multi-path linguistic representations, we utilize hierarchical variation inference. The optimization objective of a hierarchical speech synthesizer can be defined as follows:

3.2.4 Hierarchical Adaptive Generator
For semantic-to-waveform generation, we introduce the HAG G which comprises of source generator Gs and waveform generator Gw as illustrated in Fig 3. The generated representations including acoustic representation za and style representation s are fed to Gs, and Gs generates the refined pitch representation ph and auxiliary F0 predictor is used to enforce the F0 information on ph as follows:

3.2.5 Bidirectional Transformer Flow
Previously, VITS utilized a normalizing flow to improve the expressiveness of the prior distribution, which possessed the ability to bridge the posterior and prior distributions well, such that the audio quality was significantly improved. However, there is a train-inference mismatch problem and limitations on speaker adaptation in this framework. Therefore, we propose BiT-Flow, which is a bidirectional Transformer-based normalizing flow. First, we adopt the bidirectional normalizing flow proposed by NaturalSpeech [70]. We also replace WaveNet-based adaptive networks with convolutional feedforward-based Transformer networks [20] to capture a large context in the latent representation. Unlike VITS2, we utilize AdaLN-Zero in Transformer block [62] and train the blocks bidirectionally with dropout. The details are illustrated in Fig 3 For efficient training, we sliced audio sequence during training the model so we do not utilize a positional embedding in Transformer networks.
3.2.6 Prosody Distillation
We utilize prosody distillation to enhance the linguistic representation zsr from the speaker-related source-filter encoder. zsr is fed to the prosody decoder to reconstruct the first 20 bins of the Mel-spectrogram containing the prosody information. By conditioning the voice style representation, we enforce zsr to learn speaker-related prosody to enhance linguistic information. We train the model with prosody loss Lprosody which minimizes the l1 distance between the 20 bins of the GT and the reconstructed Mel-spectrogram.
3.2.7 Unconditional Generation
Following [45], we utilize unconditional generation in a hierarchical adaptive generator for progressive speaker adaptation. The use of unconditional generation makes the acoustic representations adopt speaker characteristics, thus improving the speaker adaptation performance in the entire model. We simply replace the voice style representations with the null style embedding ∅ with a 10% chance during training. In the inference stage, we utilize only the target voice style representation for conditional generation.
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
Authors:
(1) Sang-Hoon Lee, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea;
(2) Ha-Yeong Choi, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea;
(3) Seung-Bin Kim, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea;
(4) Seong-Whan Lee, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea and a Corresponding author.