
Authors:
(1) Robert Honig, ETH Zurich ([email protected]);
(2) Javier Rando, ETH Zurich ([email protected]);
(3) Nicholas Carlini, Google DeepMind;
(4) Florian Tramer, ETH Zurich ([email protected]).
Table of Links
-
Discussion and Broader Impact, Acknowledgements, and References
D. Differences with Glaze Finetuning
H. Existing Style Mimicry Protections
Abstract
Artists are increasingly concerned about advancements in image generation models that can closely replicate their unique artistic styles. In response, several protection tools against style mimicry have been developed that incorporate small adversarial perturbations into artworks published online. In this work, we evaluate the effectiveness of popular protections—with millions of downloads—and show they only provide a false sense of security. We find that low-effort and “off-the-shelf” techniques, such as image upscaling, are sufficient to create robust mimicry methods that significantly degrade existing protections. Through a user study, we demonstrate that all existing protections can be easily bypassed, leaving artists vulnerable to style mimicry. We caution that tools based on adversarial perturbations cannot reliably protect artists from the misuse of generative AI, and urge the development of alternative protective solutions.
1 Introduction
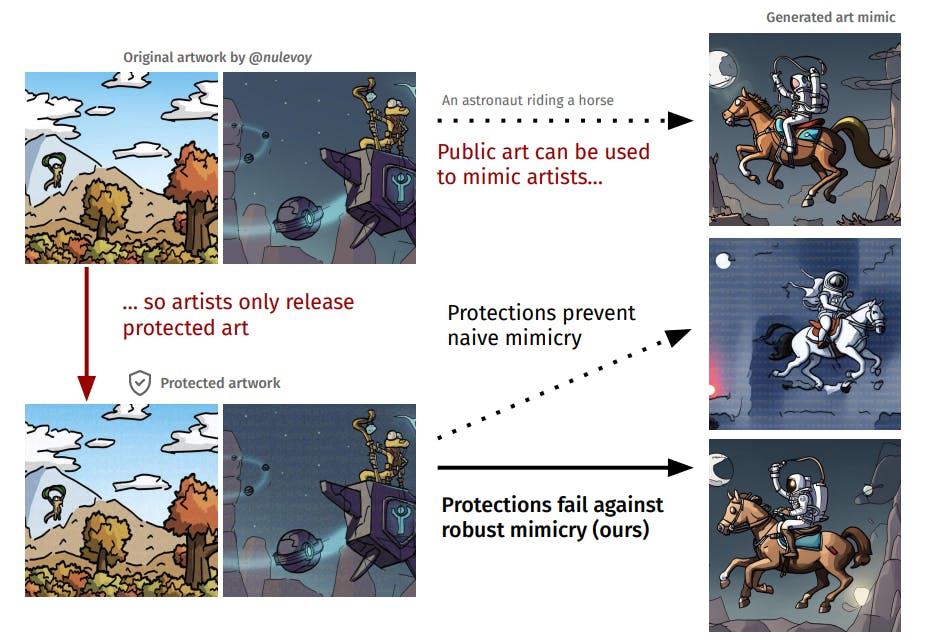
Style mimicry is a popular application of text-to-image generative models. Given a few images from an artist, a model can be finetuned to generate new images in that style (e.g., a spaceship in the style of Van Gogh). But style mimicry has the potential to cause significant harm if misused. In particular, many contemporary artists worry that others could now produce images that copy their unique art style, and potentially steal away customers (Heikkila¨, 2022). As a response, several protections have been developed to protect artists from style mimicry (Shan et al., 2023a; Van Le et al., 2023; Liang et al., 2023). These protections add adversarial perturbations to images that artists publish online, in order to inhibit the finetuning process. These protections have received significant attention from the media—with features in the New York Times (Hill, 2023), CNN (Thorbecke, 2023) and Scientific American (Leffer, 2023)—and have been downloaded over 1M times (Shan et al., 2023a).
Yet, it is unclear to what extent these tools actually protect artists against style mimicry, especially if someone actively attempts to circumvent them (Radiya-Dixit et al., 2021). In this work, we show that state-of-the-art style protection tools—Glaze (Shan et al., 2023a), Mist (Liang et al., 2023) and Anti-DreamBooth (Van Le et al., 2023)—are ineffective when faced with simple robust mimicry methods. The robust mimicry methods we consider range from low-effort strategies—such as using a different finetuning script, or adding Gaussian noise to the images before training—to multi-step strategies that combine off-the-shelf tools. We validate our results with a user study, which reveals that robust mimicry methods can produce results indistinguishable in quality from those obtained from unprotected artworks (see Figure 1 for an illustrative example).
We show that existing protection tools merely provide a false sense of security. Our robust mimicry methods do not require the development of new tools or fine-tuneing methods, but only carefully

combining standard image processing techniques which already existed at the time that these protection tools were first introduced!. Therefore, we believe that even low-skilled forgers could have easily circumvented these tools since their inception.
Although we evaluate specific protection tools that exist today, the limitations of style mimicry protections are inherent. Artists are necessarily at a disadvantage since they have to act first (i.e., once someone downloads protected art, the protection can no longer be changed). To be effective, protective tools face the challenging task of creating perturbations that transfer to any finetuning technique, even ones chosen adaptively in the future. A similar conclusion was drawn by Radiya-Dixit et al. (Radiya-Dixit et al., 2021), who argued that adversarial perturbations cannot protect users from facial recognition systems. We thus caution that adversarial machine learning techniques will not be able to reliably protect artists from generative style mimicry, and urge the development of alternative measures to protect artists.
We disclosed our results to the affected protection tools prior to publication, so that they could determine the best course of action for existing users.
This paper is